Оглавление:
В основе научных знаний лежат наблюдения за изучаемыми объектами и процессами, присущими данным объектам. Однако, ясно, что единичное наблюдение вряд ли позволит сразу установить свойства наблюдаемого объекта. Поэтому для установления свойств и связей изучаемого объекта его приходится наблюдать многократно, а затем результаты наблюдений обрабатывать и лишь после этого делать выводы.
| Если что-то непонятно — вы всегда можете написать мне в WhatsApp и я вам помогу! |
Математическая статистика
В математической статистике изучаются случайные величины и системы случайных величин при помощи наблюдений. В связи с этим в математической статистике (которая достаточно долго развивалась независимо от теории вероятностей) случайные величины принято называть наблюдаемыми признаками.
Возможно эта страница вам будет полезна:
| Предмет теория вероятностей и математическая статистика |
Первичная обработка результатов измерений
Пусть рассматривается некоторый наблюдаемый признак Х. Назовем генеральной совокупностью наблюдаемого признака Х множество значений, которые может принимать этот наблюдаемый признак.
Набор значений 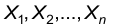 , являющихся результатами наблюдений (измерений) наблюдаемого признака Х, назовем выборкой объема п из генеральной совокупности.
, являющихся результатами наблюдений (измерений) наблюдаемого признака Х, назовем выборкой объема п из генеральной совокупности.
Отметим, что на выборку можно смотреть с двух точек зрения:
1. -результаты измерений (конкретные числа),
2. — совокупность п случайных величин, имеющих такие же распределения как и наблюдаемый признак.
Разумеется, первой точки зрения на выборку придерживаются после проведения измерений, а второй – до проведения измерений.
В этом пункте мы будем рассматривать выборку как результаты наблюдений. Как правило, объем выборки весьма велик и это мешает увидеть закономерности, присущие наблюдаемому признаку. В связи с этим возникает задача о выборе сравнительно небольшого числа представителей выборки так, чтобы были сохранены основные закономерности, описываемые исходной выборкой. Процедура решения этой задачи называется первичной обработкой результатов измерений.
Первичная обработка проводится по-разному в зависимости от типа наблюдаемого признака:
1. Ранжирование.
Пусть наблюдаемый признак Х является дискретной СВ. В этом случае, как известно, генеральная совокупность представляет собой не более чем счетное множество. В таком случае, всякая выборка есть конечное подмножество этого множества. Под ранжированием понимают расположение в порядке возрастания значений, упомянутых в выборке, с указанием количества повторов каждого значения.
Поясним сказанное примером.
Курсовая работа с примером решения № 1.
Пусть Х – количество сбоев станка в течении смены. В результате проведения наблюдений получены следующие данные: 5,1,3,2,4,1,2,3,4,5,3,2,2,1,2,5,4,4,4,3,1,2,3,4,5. Требуется провести первичную обработку результатов измерений.
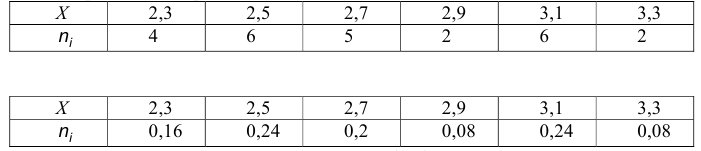
В данном случае, очевидно, что наблюдаемый признак является ДСВ, поэтому первичная обработка есть ранжирование:

Значения 1,2,3,4,5, встречающиеся в приведенной таблице, называют вариантами, числа 4,6,5,6,4 – их частотами соответственно, а саму таблицу — вариационным рядом частот.
Отметим, что сумма частот 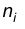 совпадает с объемом выборки: 4+6+5+6+4=25.
совпадает с объемом выборки: 4+6+5+6+4=25.
Иногда вместо вариационного ряда частот используют вариационный ряд относительных частот, который отличается от вариационного ряда частот тем, что вместо частот используются относительные частоты 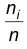 . Ясно, что сумма относительных частот обязательно равна 1:
. Ясно, что сумма относительных частот обязательно равна 1: 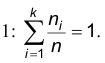
В приведенном выше примере вариационный ряд относительных частот имеет вид:

2. Интервальная обработка выборки.
В этом пункте мы рассматриваем случай, когда генеральная совокупность не является дискретным множеством. Нашей целью является построение вариационных рядов, аналогичных рассмотренным выше. Достигается поставленная цель при помощи, описываемого ниже эмпирического алгоритма, называемого интервальной обработкой выборки.
По выборке объема n строят, так называемый интервальный ряд частот:
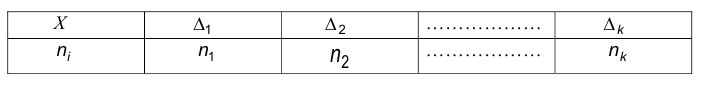
где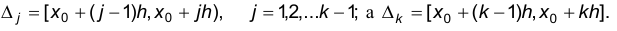
При этом число интервалов расчитывается по эмпирической формуле Стерджеса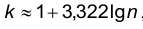 шаг h определяется по формуле
шаг h определяется по формуле 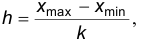 а через
а через 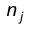 обозначают число наблюдений, попавших в интервал
обозначают число наблюдений, попавших в интервал 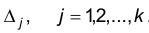 . В качестве
. В качестве 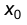 рекомендуют выбирать
рекомендуют выбирать 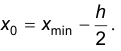
После построения интервального ряда частот вариационный ряд частот получают из него, заменяя каждый из интервалов его одним представителем.
Как правило, в качестве представителя интервала берут его середину.
Курсовая работа с примером решения № 2.
Построить вариационный ряд частот и относительных частот по результатам измерений:
2,3; 2,5; 2,7; 2,35; 2,71; 2,32; 2,36; 2,44; 2,61; 2,67; 2,83; 2,86; 3,01; 3,12; 3,14; 2,61;2,49; 2,57; 2,52; 2,54; 3,03; 3,05.
Очевидно, в рассматриваемом случае 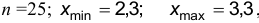 поэтому
поэтому
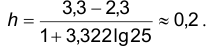
Руководствуясь изложенными выше соображениями, строим интервальный ряд частот:

Заменяя интервалы их серединами, получаем вариационный ряд частот, а затем вариационный ряд относительных частот:
Всюду ниже мы считаем, что первичная обработка результатов измерений произведена и выборка представлена в виде вариационного ряда частот или относительных частот.
Графическое изображение результатов измерений. Гистограмма. Полигон распределения
Гистограмма служит для графического изображения интервальных рядов и строится следующим образом: на оси абсцисс наносятся интервалы, в которых принимает значения наблюдаемый признак, а на оси ординат – частоты (относительные частоты) попадания наблюдаемого признака в соответствующий интервал. Гистограммой является ступенчатая фигура, ограничиваемая построенными таким образом прямоугольниками.
Для определенности будем считать, что задан интервальный ряд частот.
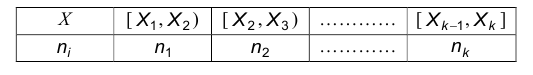
Тогда, согласно определению, данному выше, гистограмма этого интервального ряда имеет следующий вид:
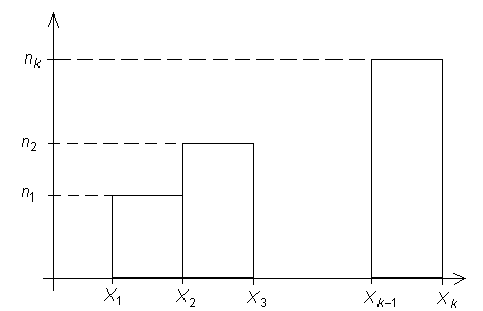
Вариационные ряды геометрически изображают при помощи полигонов частот или относительных частот. Пусть, для определенности, задан вариационный ряд частот
63
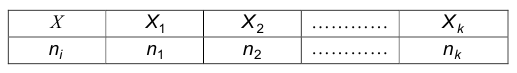
На плоскость наносят точки с координатами 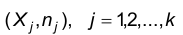 и соединяют их ломаной. Крайние левую и правую точки соединяют с ближайшими точками вида
и соединяют их ломаной. Крайние левую и правую точки соединяют с ближайшими точками вида 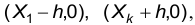 где h – шаг. Таким образом, полигон имеет следующий вид:
где h – шаг. Таким образом, полигон имеет следующий вид:
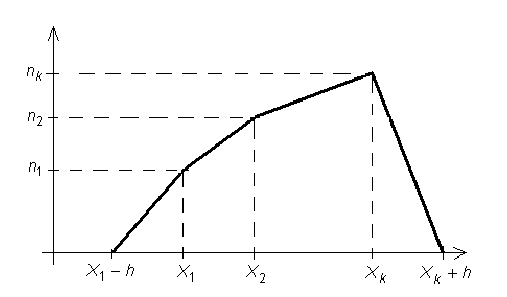
Замечание. Иногда для графического изображения вариационных рядов используют не полигоны, а, так называемые, куммулятивные кривые. Например, куммулятивная кривая частот есть ломанная, соединяющая точки 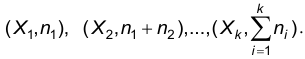 Аналогичным образом определяется куммулятивная кривая относительных частот.
Аналогичным образом определяется куммулятивная кривая относительных частот.
Эмпирическая функция распределения. Эмпирические числовые характеристики
Пусть наблюдаемый признак задан вариационным рядом относительных частот
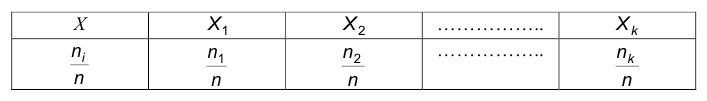
Поскольку 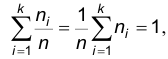 то вариационный ряд относительных частот является законом распределения для некоторой дискретной случайной величины
то вариационный ряд относительных частот является законом распределения для некоторой дискретной случайной величины 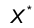 . Случайную величину называют эмпирической СВ, соответствующей рассматриваемой выборке наблюдаемого признака Х. Разумеется при изменении выборки эмпирическая СВ также меняется. Обозначим через
. Случайную величину называют эмпирической СВ, соответствующей рассматриваемой выборке наблюдаемого признака Х. Разумеется при изменении выборки эмпирическая СВ также меняется. Обозначим через 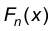 функцию распределения СВ , построенную по выборке объема n. Эту функцию называют эмпирической функцией распределения СВ Х. Эмпирическая функция распределения при неограниченном увеличении объема выборки в некотором смысле приближается к функции распределения наблюдаемого признака Х. Точнее, имеет место следующее утверждение.
функцию распределения СВ , построенную по выборке объема n. Эту функцию называют эмпирической функцией распределения СВ Х. Эмпирическая функция распределения при неограниченном увеличении объема выборки в некотором смысле приближается к функции распределения наблюдаемого признака Х. Точнее, имеет место следующее утверждение.
Теорема Гливенко-Кантелли. Эмпирическая функция распределения при неограниченном увеличении объема выборки сходится к функции распределения наблюдаемого признака по вероятности равномерно по х, то есть 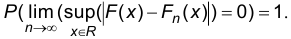
Определение. Числовые характеристики эмпирической СВ называются эмпирическими числовыми характеристиками. Это означает, что определены эмпирическое математическое ожидание, эмпирическая дисперсия, эмпирическое среднее квадратическое отклонение. Условимся в обозначениях эмпирических числовых характеристик употреблять в качестве нижнего индекса букву «э». Таким образом, по определению:
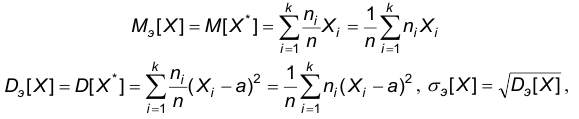
при этом, как обычно,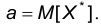
Теорема Гливенко-Кантелли наводит на мысль о том, что эмпирические числовые характеристики должны быть приближенно равны соответствующим числовым характеристикам наблюдаемого признака.
Понятие о точечном оценивании параметров
Пусть Х – наблюдаемый признак с известным видом функции (плотности, закона) распределения. Будем предполагать, что функция распределения зависит от параметров: 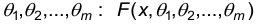 .
.
Назовем точечной оценкой параметра 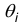 всякую формулу, которая по результатам выборки позволяет расчитывать приближенное значение параметра:
всякую формулу, которая по результатам выборки позволяет расчитывать приближенное значение параметра: 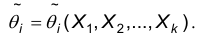
Отметим, что точечную оценку, как и выборку, можно рассматривать с двух точек зрения: как расчетную формулу или как случайную величину.
Курсовая работа с примером решения № 3.
Как известно, нормально распределенная СВ задается плотностью распределения
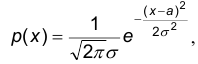
зависящей от двух параметров a и 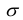 . Поскольку при этом a является математическим ожиданием, а — средним квдратическим отклонением, то учитывая теорему Гливенко-Кантелли, естественно предположить, что
. Поскольку при этом a является математическим ожиданием, а — средним квдратическим отклонением, то учитывая теорему Гливенко-Кантелли, естественно предположить, что 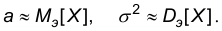 Эти соображения приводят к следующей паре точечных оценок
Эти соображения приводят к следующей паре точечных оценок
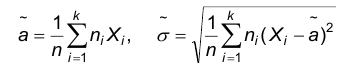
Замечание. Разумеется, для одного и того же параметра, как правило, существует много оценок. Например, в предыдущем примере в качестве оценки математического ожидания можно выбрать первое из производимых измерений наблюдаемого признака.
В связи с этим, среди оценок следует выбирать наилучшие. Для отбора используют следующие критерии:
1. Несмещенность. Точечная оценка параметра называется несмещенной, если математическое ожидание оценки совпадает с истинным значением этого параметра: 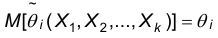
2. Состоятельность. Точечная оценка параметра называется состоятельной, если при неограниченном увеличении объема выборки 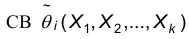 сходится по вероятности к истинному значению этого параметра, т.е. если
сходится по вероятности к истинному значению этого параметра, т.е. если 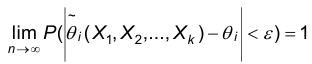 каково бы ни было
каково бы ни было 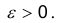
3. Эффективность. Несмещенная точечная оценка параметра называется эффективной, если она имеет наименьшую дисперсию среди всех несмещенных оценок рассматриваемого параметра.
Замечание. При формулировке критериев, предъявляемых к точечным оценкам мы рассматривали последние как случайные величины.
Точечная оценка математического ожидания
Пусть задан вариационный ряд частот наблюдаемого признака Х. Назовем выборочным средним и будем обозначать 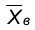 среднее арифметическое значений, наблюденных в выборке:
среднее арифметическое значений, наблюденных в выборке: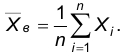 Учитывая повторяющиеся значения, последнее выражение можно преобразовать следующим образом:
Учитывая повторяющиеся значения, последнее выражение можно преобразовать следующим образом:
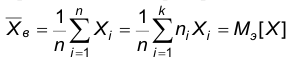
Таким образом, выборочное среднее является эмпирическим математическим ожиданием и, поэтому, во-первых, обладает всеми свойствами математического ожидания, во-вторых, является точечной оценкой математического ожидания наблюдаемого признака.
Более того, эта оценка яляется наилучшей в силу следующей теоремы.
Теорема. Выборочное среднее есть несмещенная, состоятельная, эффективная оценка математического ожидания.
Доказательство. Учитывая, что результаты наблюдений можно рассматривать как случайные величины, имеющие такое же распределение, как и наблюдаемый признак, получаем
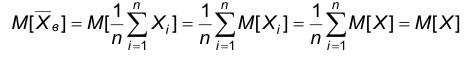
Таким образом, несмещенность доказана.
С другой стороны, в силу теоремы закона больших чисел
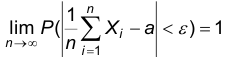
каково бы ни было 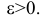 Последнее означает состоятельность выборочного среднего как точечной оценки математического ожидания. Доказательство эффективности проводится по следующей схеме. Сначала показывают, что минимумом для дисперсий среди всех несмещенных оценок математического ожидания является величина
Последнее означает состоятельность выборочного среднего как точечной оценки математического ожидания. Доказательство эффективности проводится по следующей схеме. Сначала показывают, что минимумом для дисперсий среди всех несмещенных оценок математического ожидания является величина 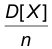 , а затем замечают, что
, а затем замечают, что 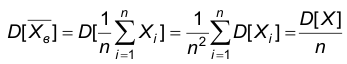
Теорема доказана.
Точечные оценки дисперсии
По аналогии с математическим ожиданием в качестве точечной оценки дисперсии будем считать точечной оценкой дисперсии среднюю выборочную дисперсию:
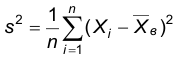
Теорема. Оценка 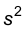 является смещенной, а именно
является смещенной, а именно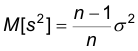 , где
, где 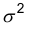 — дисперсия наблюдаемого признака.
— дисперсия наблюдаемого признака.
Доказательство. Пусть a –математическое ожидание наблюдаемого признака, тогда
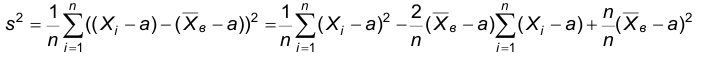
Принимая во внимание, что 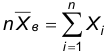 получим
получим
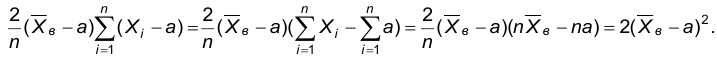
Тогда
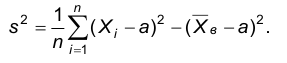
Следовательно,
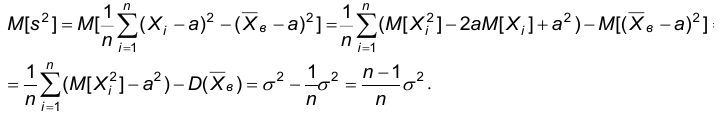
Теорема доказана.
Следствие. Несмещенной оценкой дисперсии является
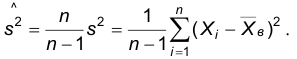
Эту оценку называют исправленной выборочной дисперсией. Дробь 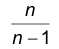 называют поправкой Бесселя. Очевидно, эта поправка стремится к 1 при увеличении объема выборки и при n>50 разница между исправленной дисперсией и дисперсией выборки практически неощутима. Пользуясь законом больших чисел можно показать, что обе рассмотренные оценки являются состоятельными. Однако, исправленная выборочная дисперсия не является эффективной оценкой дисперсии. Можно показать, что несмещенной, состоятельной, эффективной оценкой дисперсии является следующая оценка
называют поправкой Бесселя. Очевидно, эта поправка стремится к 1 при увеличении объема выборки и при n>50 разница между исправленной дисперсией и дисперсией выборки практически неощутима. Пользуясь законом больших чисел можно показать, что обе рассмотренные оценки являются состоятельными. Однако, исправленная выборочная дисперсия не является эффективной оценкой дисперсии. Можно показать, что несмещенной, состоятельной, эффективной оценкой дисперсии является следующая оценка 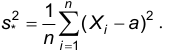 Однако, эта оценка практически неприменима, ибо для ее построения необходимо знание точного значения математического ожидания.
Однако, эта оценка практически неприменима, ибо для ее построения необходимо знание точного значения математического ожидания.
Методы построения точечных оценок
1.Метод максимального правдоподобия.
Пусть 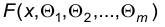 — функция распределения, плотность распределения или вероятность того, что случайная величина Х примет значение х.
— функция распределения, плотность распределения или вероятность того, что случайная величина Х примет значение х.
Ясно, что первые две функции используют для непрерывных наблюдаемых признаков, а первую и третью – для дискретных наблюдаемых признаков.
Назовем функцией правдоподобия следующую функцию
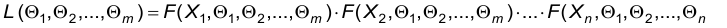
где — выборка объема и значений Х.
Теорема. Пусть 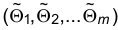 — точка максимума функции L, тогда
— точка максимума функции L, тогда 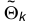 есть состоятельная оценка параметра
есть состоятельная оценка параметра 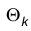 .
.
Эту теорему мы приводим без доказательства.
Из приведенной теоремы вытекает следующая схема поиска точечных оценок:
1. Составить функцию максимального правдоподобия L.
2. Исследовать функцию L на максимум, для чего составить и решить систему уравнений
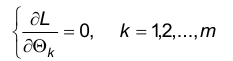
После чего проверить, что найденные решения этой системы доставляют максимум функции L.
3. Выписать полученные точечные оценки.
Замечание. Если f(x) возрастающая функция, то функция L и f(L) имеют максимумы в одних и тех же точках. Поэтому в пункте 2 схемы можно вместо функции L использовать функцию f(L), что иногда проще при удачном выборе функции f(x).
Курсовая работа с примером решения № 4.
Построить точечные оценки параметров а и нормально распределенного признака по результатам выборки
Поскольку плотность распределения в рассматриваемом случае имеет вид: 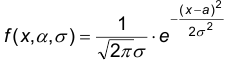 , то функция правдоподобия имеет вид
, то функция правдоподобия имеет вид
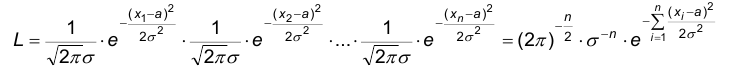
Будем рассматривать вместо функции L, следую замечанию, функцию lnL: .
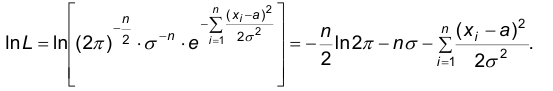
Тогда
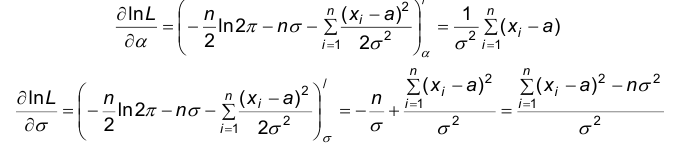
Приравнивая к нулю частные производные, получаем
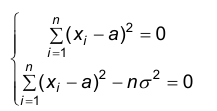
Решая эту систему относительно а и , получаем:
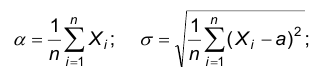
Можно проверить, что полученные значения действительно доставляют максимум функции lnL.
Следствие. В рассмотренном примере получены следующие оценки математического ожидания и дисперсии
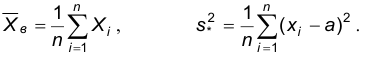
2. Метод моментов.
Пусть 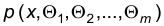 — плотность распределения признака Х, а — выборка объема n. Представим эту выборку в виде вариационного ряда относительных частот:
— плотность распределения признака Х, а — выборка объема n. Представим эту выборку в виде вариационного ряда относительных частот:
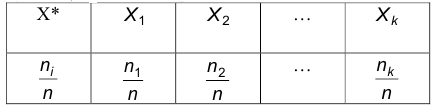
Этот ряд, как отмечалось выше, определяет эмпирическую случайную величину Х*, которая является некоторым приближением наблюдаемого признака Х. Последнее означает, что моменты произвольных порядков величин Х и Х* должны быть приблизительно равны:
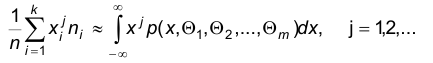
Выбирая m уравнений, получаем систему, решения которой дают оценки параметров 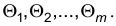
Курсовая работа с примером решения № 5.
Методом моментов построить оценку параметра 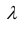 для распределения Пуассона.
для распределения Пуассона.
Плотность распределения имеет вид
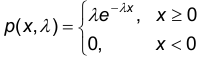
где: 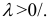
Найдем моменты первого порядка случайных величин Х и Х*:
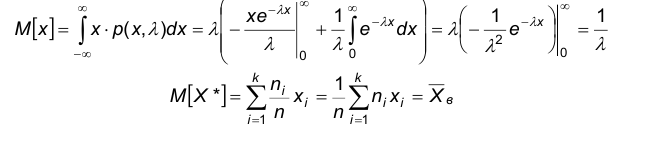
Следовательно, 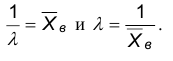
Доверительное оценивание параметров
Пусть, как и раньше, наблюдаемый признак Х зависит от некоторых параметров. Пусть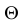 — один из этих параметров.
— один из этих параметров.
Интервал 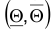 назовем доверительным, соответствующим доверительной вероятности
назовем доверительным, соответствующим доверительной вероятности 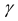 , если вероятность того, что истинное значение параметра находится на этом интервале есть :
, если вероятность того, что истинное значение параметра находится на этом интервале есть :
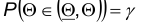
Как правило, в качестве доверительной вероятности выбирают достаточно близкое к единице значение. Стандартными являются следующие значения доверительной вероятности:
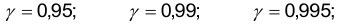
Такие значения для выбираются для того, чтобы получать информацию об изучаемом параметре с вероятностью близкой к единице, т.е. почти наверняка. В связи с этим иногда доверительную вероятность называют надежностью.
Замечание. Иногда вместо доверительной вероятности (надежности) использую величину 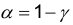 , называемую уровнем значимости.
, называемую уровнем значимости.
Построение доверительного интервала для математического ожидания нормального распределения при известном .
Пусть наблюдаемый признак Х распределен по нормальному закону и известно его среднее квадратическое отклонение .
Рассмотрим случайную величину
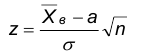
где а — математическое ожидание Х.
Теорема. Случайная величина z распределена по нормальному закону с параметрами 0,1. При доказательстве несмещенности выборочного среднего было показано, что 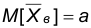 , поэтому
, поэтому
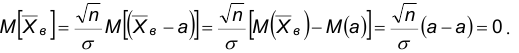
Покажем, что 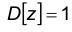
В самом деле,
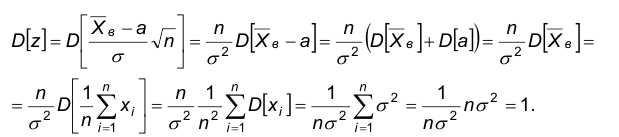
Теорема доказана.
Обозначим через 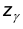 решение уравнения
решение уравнения
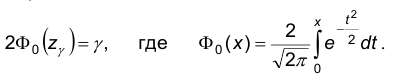
Функция 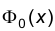 задается таблично и решение выписанного уравнения также определяется при помощи таблиц. При этом следует учитывать, что функция нечетна, т.е., что
задается таблично и решение выписанного уравнения также определяется при помощи таблиц. При этом следует учитывать, что функция нечетна, т.е., что 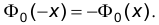
Найдем теперь вероятность того, что 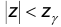 . Поскольку случайная величина z распределена по нормальному закону с параметрами 0,1, имеем:
. Поскольку случайная величина z распределена по нормальному закону с параметрами 0,1, имеем:
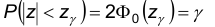
С другой стороны, неравенство эквивалентно следующим:
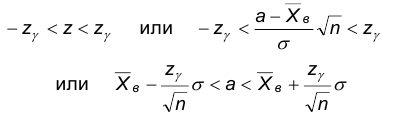
Следовательно, 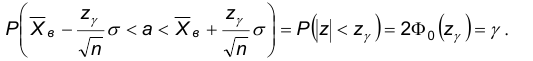
По определению доверительного интервала имеем, что интервал
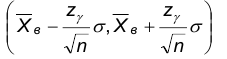
в является доверительным для математического ожидания с доверительной вероятностью .
Доверительную вероятность называют иногда надежностью.
Кроме того, вместо надежности задают иногда уровень значимости а , связанный с надежностью соотношением 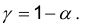
Курсовая работа с примером решения № 6.
Случайная величина Х имеет нормальное распределение со средним квадратическим отклонением 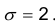 Найти доверительный интервал по выборке 2,1; 2,3; 2,4; 2,6; 2,8; 2,7; 2,5;2,.4; 2,7; с уровнем значимости 0,05.
Найти доверительный интервал по выборке 2,1; 2,3; 2,4; 2,6; 2,8; 2,7; 2,5;2,.4; 2,7; с уровнем значимости 0,05.
Доверительная вероятность (надежность) в рассматриваемом случае такова = 1 — 0,05 = 0,95.
Найдем 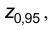 , решив уравнение
, решив уравнение 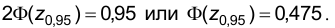
Пользуясь таблицами для функции Ф(x) , получаем 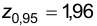 Очевидно объем выборки в рассматриваемом случае n=9. Найдем
Очевидно объем выборки в рассматриваемом случае n=9. Найдем 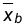 :
:
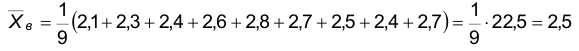
Следовательно, искомый доверительный интервал имеет вид:
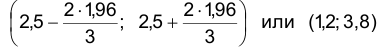
Построение доверительного интервала для математического ожидания нормального распределения при известном .
Пусть — выборка объема из генеральной совокупности признака Х, распределенного по нормальному закону. Случайная величина
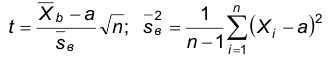
называется распределенным по закону Стьюдента (t — распределение) c k=n-1 числом степеней свободы.
Для этой случайной величины составлен в виде таблицы закон распределения, который называют t – распределением Стьюдента. При помощи этих таблиц может быть решена задача нахождения по заданному значения 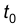 , удовлетворяющее уравнению:
, удовлетворяющее уравнению:
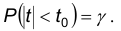
Величина оказывается зависящей от и числа степеней свободы k=n-1 и, поэтому в дальнейшем, обозначается 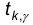 . В таблице находится на пересечении столбца соответсвующего = 0,95; 0,99; 0,995; и строки, указывающей число степеней свободы.
. В таблице находится на пересечении столбца соответсвующего = 0,95; 0,99; 0,995; и строки, указывающей число степеней свободы.
Рассмотрим неравенство 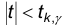 , где таково, что
, где таково, что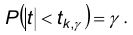 Это неравенство эквивалентно следующему
Это неравенство эквивалентно следующему 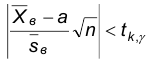 , отсюда
, отсюда
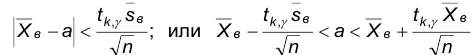
Поскольку все записанные неравенства эквивалентны, то
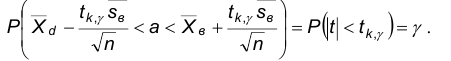
Последнее означает, что интервал 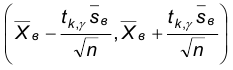 , является доверительным, соответствующим надежности .
, является доверительным, соответствующим надежности .
Курсовая работа с примером решения № 7.
Случайная величина Х имеет нормальное распределение. Найти доверительный интервал для математического ожидания по выборке: 5, 6, 4, 6, 7, 4, 8, 7, 9, 4 с уровнем значимости 0,05.
По выборке находим 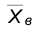 и
и 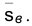
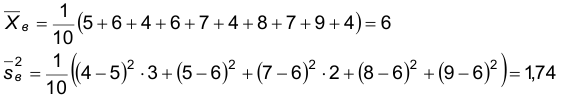
Найдем по таблице
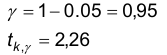
Следовательно, искомый интервал имеет вид
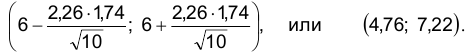
Проверка статистических гипотез
Под статистической гипотезой будем понимать всякое высказывание о наблюдаемом признаке, которое может быть проверено по результатам выборки.
Пусть 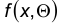 — закон распределения наблюдаемого признака Х, зависящий от параметра, истинное значение которого нам неизвестно.
— закон распределения наблюдаемого признака Х, зависящий от параметра, истинное значение которого нам неизвестно.
Предположим, что нам необходимо проверить гипотезу 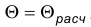 . Назовем эту гипотезу нулевой и будем обозначать через
. Назовем эту гипотезу нулевой и будем обозначать через 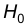 . Гипотезу
. Гипотезу 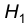 , состоящую в том, что
, состоящую в том, что 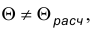 назовем конкурирующей или альтернативной.
назовем конкурирующей или альтернативной.
Нашей задачей является по статистическим данным (по выборке) из гипотез и принять какую-либо и, следовательно, отвергнуть альтернативную гипотезу. При этом мы можем совершать следующие ошибки:
1. Гипотеза отвергается, но является верной. Такую ошибку назовем ошибкой первого рода.
2. Гипотеза принимается, но является неверной. Такую ошибку назовем ошибкой второго рода..
Схематически решение сформулированной задачи состоит в следующем: в зависимости от вида гипотезы по выборке рассчитывают некоторую величину, называемую статистикой. Это значение называют расчетным значением статистики 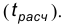 С другой стороны, статистику подбирают так, что для нее известно, так называемое, теоретическое значение
С другой стороны, статистику подбирают так, что для нее известно, так называемое, теоретическое значение 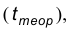 определяемое по известному виду распределения. Расчетное и теоретическое значения статистики сравниваются и при этом если, в некотором смысле, они мало отличаются, то нет оснований отвергать гипотезу, а если различия между теоретическим значением статистики и ее расчетным значением существенны, то нулевая гипотеза отвергается. Как правило, сравнение указанных величин состоит в проверке выполнения неравенств:
определяемое по известному виду распределения. Расчетное и теоретическое значения статистики сравниваются и при этом если, в некотором смысле, они мало отличаются, то нет оснований отвергать гипотезу, а если различия между теоретическим значением статистики и ее расчетным значением существенны, то нулевая гипотеза отвергается. Как правило, сравнение указанных величин состоит в проверке выполнения неравенств: 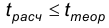 или
или 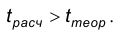 Тем самым множество выборок разбивается на 2 непересекающихся подмножества. Одно из них называется областью допустимых значений и описывается неравенством , а второе называется критической областью и описывается неравенством расч теор Область допустимых значений обозначают, как правило, через 0, а критическую область – через W.
Тем самым множество выборок разбивается на 2 непересекающихся подмножества. Одно из них называется областью допустимых значений и описывается неравенством , а второе называется критической областью и описывается неравенством расч теор Область допустимых значений обозначают, как правило, через 0, а критическую область – через W.
Проверка гипотезы о равенстве центров распределения двух нормальных генеральных совокупностей при известных дисперсиях
Пусть Х и Y – два наблюдаемых признака, подчиненных нормальному распределению. Будем считать, что дисперсии 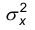 и
и 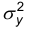 известны. Будем считать, что выборки и
известны. Будем считать, что выборки и 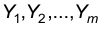 независимы. Тогда выборочные средние
независимы. Тогда выборочные средние 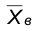 и
и 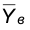 также независимы и распределены по нормальному закону. Это означает, что и разность
также независимы и распределены по нормальному закону. Это означает, что и разность 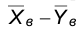 распределена по нормальному закону. Найдем параметры распределения этой случайной величины, предполагая, что гипотеза , состоящая в том, что
распределена по нормальному закону. Найдем параметры распределения этой случайной величины, предполагая, что гипотеза , состоящая в том, что 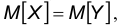 верна. Тогда
верна. Тогда
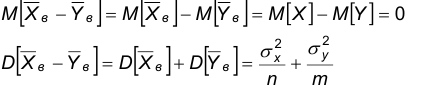
Последние равенства означают, что случайная величина 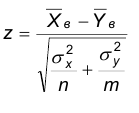 распределена по нормальному закону с параметрами (0, 1).
распределена по нормальному закону с параметрами (0, 1).
Пользуясь статистикой z, построим критическую область и область допустимых значений для гипотез:
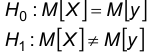
Пусть задана вероятность 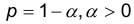 , с которой мы принимаем решение о совпадении центров, т.е. гипотезу . При этом величина а называется уровнем значимости.
, с которой мы принимаем решение о совпадении центров, т.е. гипотезу . При этом величина а называется уровнем значимости.
Рассмотрим уравнение
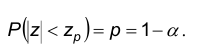
Решением этого уравнения будет 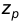 находится по таблицам для нормального распределения.
находится по таблицам для нормального распределения.
Последнее означает, что область допустимых значений описывается неравенством:
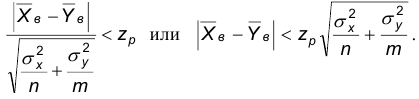
Следовательно, в рассматриваемом случае критическая область задается неравенством:
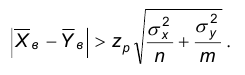
Курсовая работа с примером решения № 8.
По результатам выборок двух наблюдаемых признаков, распределенных по нормальному закону с дисперсиями 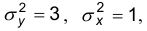 проверить гипотезу о совпадении центров, приняв уровень значимости
проверить гипотезу о совпадении центров, приняв уровень значимости 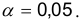
X: 2,1; 2,2; 2,3; 2,15; 2,4; 2,5; 2,4; 2,3; 2,1; 2,2
Y: 2,3; 2,4; 2,8; 2,0; 2,0; 2,6; 2,7; 2,8; 2,9; 3,0; 2,9
Выполним необходимые расчеты:
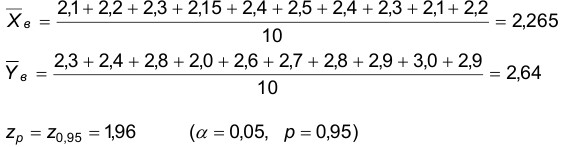
Поэтому 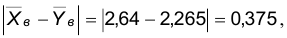 а
а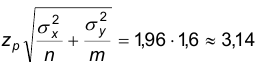
Так как 0,375<3,14, то выборка принадлежит области допустимых значений и нет оснований отвергать гипотезу о равенстве центров наблюдаемых признаков.
Проверка гипотез о законе распределения. Критерий согласия 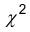 .
.
Пусть Х – наблюдаемый признак и требуется проверить гипотезу , состоящую в том, что Х подчиняется закону распределения F(x).
Произведем выборку объема n; и построим по этой выборке эмпирическую функцию распределения F*(х).
Проверка гипотезы :состоит в сравнении законов F(х) и F*(х) при помощи, так называемого, критерия согласия. Существует много различных критериев согласия. Мы рассматриваем один из них – критерий согласия .
Разобьем генеральную совокупность признака Х на l интервалов 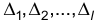 и подсчитаем число элементов, попавших на каждый из этих интервалов.
и подсчитаем число элементов, попавших на каждый из этих интервалов.
Предполагая, что гипотеза имеет место, можно найти вероятности 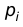 попадания случайной величины в интервал
попадания случайной величины в интервал 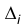 . Тогда теоретическое значение числа элементов, попавших в интервал , есть
. Тогда теоретическое значение числа элементов, попавших в интервал , есть 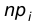 . Результаты расчетов помещаем в следующую таблицу:
. Результаты расчетов помещаем в следующую таблицу:

По построению 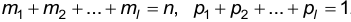
Рассмотрим следующую статистику
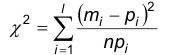
Можно показать, что эта статистика имеет распределение с k=l-r-i числом степеней свободы. Здесь r – число параметров, входящих в функцию F(x).
Значение 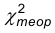 может быть найдено при помощи таблицы по числу степеней свободы k и заданному уровню значимости а.
может быть найдено при помощи таблицы по числу степеней свободы k и заданному уровню значимости а.
С другой стороны, может быть найдено расчетное значение 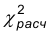 по приведенной выше формуле.
по приведенной выше формуле.
Область допустимых значений в рассматриваемом случае описывается неравенством: 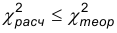 , а критическая область – неравенством
, а критическая область – неравенством 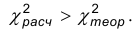 .
.
Курсовая работа с примером решения № 9.
При уровне значимости 0,05, проверить гипотезу о нормальном распределении генеральной совокупности, если выборка представлена интервальным рядом частот.

Для проверки о нормальном распределении с помощью критерия согласия , необходимо найти теоретические частоты.
1.Перейдем от интервального распределения к статистическому ряду распределения частот признака Х. В качестве представителя каждого интервала берем значение 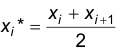

2.Вычисляем 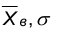
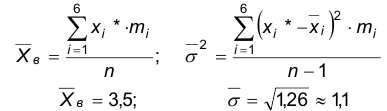
3. Нормируем случайную величину Х, т.е. переходим к величине z
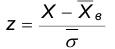
и вычисляем концы интервалов 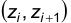
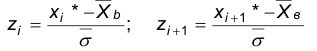
причем, наименьшее значение z полагают равным 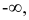 а наибольшее
а наибольшее 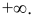
4.Вычисляем теоретические вероятности попадания в интервал по формуле 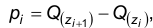 где
где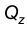 — функция Лапласа и находим искомые теоретические частоты
— функция Лапласа и находим искомые теоретические частоты 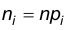 .
.
5.Вычисляем . Вычисления удобно проводить с помощью следующих таблиц.
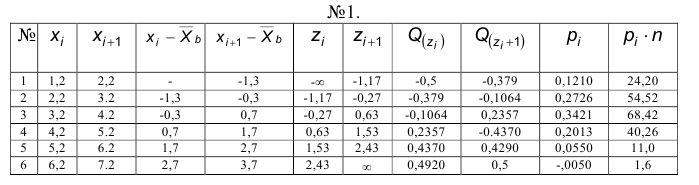
№2.
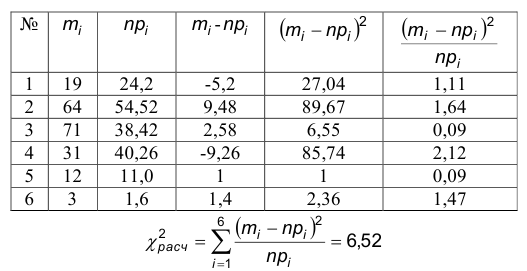
Находим по таблице – число степеней свободы у нас k=6-2-1-3, уровень значимости
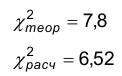
Так как 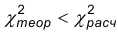 — нет оснований отвергать гипотезу о нормальном распределении.
— нет оснований отвергать гипотезу о нормальном распределении.
Возможно эти страницы вам будут полезны:
- Решение задач по теории вероятностей
- Помощь по теории вероятности
- Заказать работу по теории вероятности
- Контрольная работа по теории вероятности
- Курсовая работа по теории вероятности
- Решение задач по математической статистике
- Помощь по математической статистике
- Заказать работу по математической статистике
- Контрольная работа по математической статистике
- Теория вероятностей краткий курс для школьников и студентов