Оглавление:

| Здравствуйте! Я Людмила Анатольевна Фирмаль, занимаюсь помощью студентам более 17 лет. У меня своя команда грамотных, сильных преподавателей. Мы справимся с любой поставленной перед нами работой технического и гуманитарного плана. И неважно – она по объёму на две формулы или огромная, сложно структурированная, на 125 страниц! Нам по силам всё, поэтому не стесняйтесь, присылайте. |
| Если что-то непонятно — вы всегда можете написать мне в WhatsApp и я вам помогу! |
Как получить помощь в выполнении заданий по эконометрике
Вы можете написать сообщение в WhatsApp. После этого я оценю ваш заказ и укажу стоимость и срок выполнения вашей работы. Если условия Вас устроят, Вы оплатите, и преподаватель, который ответственен за вашу работу, начнёт выполнение и в согласованный срок или, возможно, раньше срока Вы получите файл готовой работы в личные сообщения.
Сколько стоит помощь
Стоимость помощи зависит от задания и требований Вашего учебного заведения. На цену влияют: сложность, количество заданий и срок выполнения. Поэтому для оценки стоимости заказа максимально качественно сфотографируйте или пришлите файл задания, при необходимости, загружайте поясняющие фотографии лекций, файлы методичек, указывайте свой вариант.
Какой срок выполнения
Минимальный срок выполнения составляет 2-4 дня, но помните, срочные задания оцениваются дороже.
Как оплатить
Сначала пришлите задание, я оценю, после вышлю вам форму оплаты, в которой можно оплатить с баланса мобильного телефона, картой Visa и MasterCard, apple pay, google pay.
Гарантии и исправление ошибок
В течение 1 года с момента получения Вами готового решения действует гарантия. В течении 1 года я и моя команда исправим любые ошибки.
Чуть ниже я предоставила теорию и формулы чтобы после заказанной работы вы освежили память о предмете эконометрика и смогли подготовиться к сдаче и защите работы и примеры оформления заказов по некоторым темам экономики, так я буду оформлять ваши работы если закажите у меня, это не все темы, это лишь маленькая часть их, чтобы вы понимали насколько подробно я оформляю.
Эконометрика — это наука, объединяющая различные статистические методы, используемые для наблюдения за ходом развития экономики, ее анализа и прогнозов, а также для выявления взаимосвязей между экономическими явлениями.
Возможно эта страница вам будет полезна:
| Предмет эконометрика |
Задачи эконометрики:
- Изучить экономическое явление
- Прогнозирование явлений
- Взаимосвязи явлений
Анализ невременных данных
Мы будем работать с данными, которые не являются временными, т.е. их можно переставлять местами, не меняя смысла
Случайная величина (с.в.) 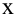 — это числовая функция, заданная на некотором вероятностном пространстве.
— это числовая функция, заданная на некотором вероятностном пространстве.
Функция распределения с.в. — это числовая функция числового аргумента, заданная равенством:
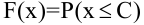
Характеристики случайной величины
I. Математическое ожидание с.в. .
Обозначается 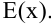 . Показывает среднее ожидаемое значение.
. Показывает среднее ожидаемое значение.
Если — дискретная с.в., то
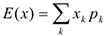
Если — непрерывная с.в., то
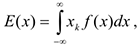
где 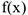 — плотность распределения.
— плотность распределения.
Т.к. при работе с данными мы не знаем вероятности, то математическое ожидание считается как
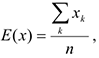
где 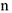 — количество наблюдений
— количество наблюдений
Свойства математического ожидания:
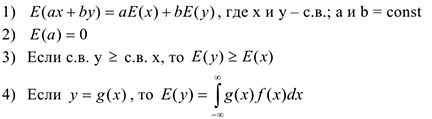
II. Дисперсия
Обозначается 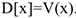 . Дисперсия — это среднее отклонение от среднего, т.е. на сколько в среднем большинство значений отклонится от математического ожидания, т.е. большинство значений будет лежать в интервале:
. Дисперсия — это среднее отклонение от среднего, т.е. на сколько в среднем большинство значений отклонится от математического ожидания, т.е. большинство значений будет лежать в интервале:
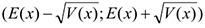
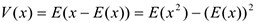
Свойства дисперсии:
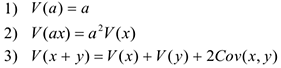
III. Ковариация
Обозначается 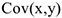 . Показывает однонаправленность двух случайных величин, т.е. ковариация — это мера линейной зависимости с.в.
. Показывает однонаправленность двух случайных величин, т.е. ковариация — это мера линейной зависимости с.в.
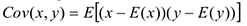
Свойства ковариации:
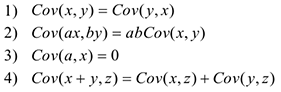
Т.к. ковариация меняется от 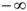 до
до 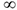 , то использовать ее как меру линейной связи, неудобно, поэтому вводят понятие корреляции.
, то использовать ее как меру линейной связи, неудобно, поэтому вводят понятие корреляции.
IV. Корреляция.
Обозначается 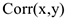 . Показывает силу линейной связи в интервале [-1;1]
. Показывает силу линейной связи в интервале [-1;1]
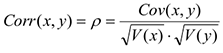
Свойства корреляции:
1) 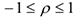
2) Если 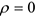 , то между
, то между 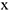 и
и 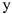 связи нет.
связи нет.
3) Если 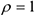 , то связь сильная положительная, т.е. рост вызывает рост и наоборот. Замечание: если , т.е. линейной связи нет, то это не значит, что нет нелинейной связи. Ложная корреляция.
, то связь сильная положительная, т.е. рост вызывает рост и наоборот. Замечание: если , т.е. линейной связи нет, то это не значит, что нет нелинейной связи. Ложная корреляция.
При использовании 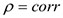 следует помнить, что он показывает наличие только линейной связи. Ложная корреляция — в ряде случаев неправильно выбраны случайные величины, между которыми ищется корреляционная связь.
следует помнить, что он показывает наличие только линейной связи. Ложная корреляция — в ряде случаев неправильно выбраны случайные величины, между которыми ищется корреляционная связь.
Пример: Если искать связь между длиной волос и ростом, то получится, что чем выше человек, тем короче у него волосы. Ошибка в том, что следует рассматривать эту зависимость отдельно по мужчинам и отдельно по женщинам.
V. Медиана
Медиана — это альтернатива определения среднего значения. Она считается по упорядоченному по возрастанию ряду из наблюдений (вариационный ряд). Показывает среднее из большинства. Обозначается med.
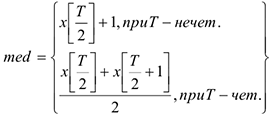
Пример: Имеются 10 человек. 9 человек получают 100$, 1 человека.
Средний доход человека
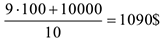
Мы видим, что среднее значение малоэффективно и не показывает реальной ситуации. Используем медиану. 1) {100,100,100,100,100,100,100,100,100,10000}
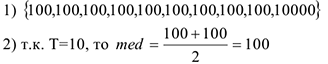
Медиана показала реальное положение вещей.
Медиана используется, когда есть несколько сильных выбросов, т.е. несколько резко выделяющихся от других значений.
VI. Мода.
Мода — это число, делящее выборку пополам, т.е. 50% значений лежит выше нее, а 50% — ниже. Обозначается mod.
Пример:
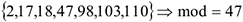
Медиана показывает насколько справедливо среднее.
VII. Оценки
Введем обозначения:
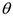 — истинное значение параметра
— истинное значение параметра
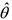 — оценка параметра
— оценка параметра
Т.к. истинное значение параметра неизвестно, то мы его находим (оцениваем) по некоторой выборке объема 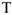 .
.
в — то число, которое скорее всего примет истинное значение. Свойства оценок:
Мы стараемся найти и подобрать выборку таким образом, чтобы по ней получить оценки, которые:
1) состоятельны, т.е. при 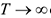 оценка стремится к истинному значению, т.е., чем больше выборка, тем точнее оценка
оценка стремится к истинному значению, т.е., чем больше выборка, тем точнее оценка 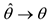
2) несмещенность, т.е. математическое ожидание оценки — это истинное значение, т.е. в среднем мы получаем истинное значение 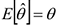
3) эффективность, т.е. дисперсия оценки — минимальна 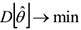
Замечание: дисперсия напрямую связана с точностью оценивания. Чем выше дисперсия, тем больше варьируемость признака, тем менее точный результат мы получаем.
Модель парной линейной регрессии
Пусть 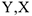 — две выборки объема .
— две выборки объема .
Возникает вопрос. Связаны ли они между собой? Если да, то как, и как выразить эту связь количественно?
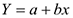
Необходимо подобрать 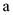 и
и 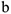 такими, чтобы линия была как можно ближе ко всем значениям, и — неизвестные параметры. Необходимо подобрать и , минимизировав меру расстояния от точек, до получившейся прямой. В качестве меры можно взять сумму квадратов отклонения от среднего
такими, чтобы линия была как можно ближе ко всем значениям, и — неизвестные параметры. Необходимо подобрать и , минимизировав меру расстояния от точек, до получившейся прямой. В качестве меры можно взять сумму квадратов отклонения от среднего
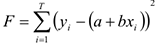
Т.е. мы суммируем квадраты расстояния в каждой точке между наблюдаемым значением и тем, что лежит на линии. Берется квадрат расстояний, чтобы большим расстояниям придать больший вес, а также избежать отрицательных значений. Иногда в качестве меры отклонения берут модуль расстояния
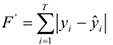
Но вычисления с модулем гораздо сложнее. Мы будем использовать квадрат отклонений. Для нахождения неизвестных параметров и , имея в распоряжении выборки 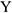 и
и 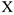 объема , нам необходимо минимизировать следующее расстояние
объема , нам необходимо минимизировать следующее расстояние
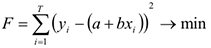
Мы ищем линию, которая будет максимально близко лежать от этих точек. Применяя метод Лагранжа в решении подобных задач, получаем что:
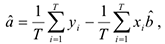
где
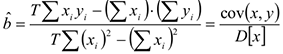
Мы получили оценки неизвестных параметров и , удовлетворяющие свойствам оценок, с помощью которых можно построить уравнение регрессии и найти качественную зависимость между и .
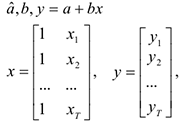
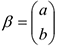 — вектор из двух букв и .
— вектор из двух букв и .
В данном случае построить регрессию, значит найти оценку вектора 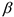 .
.
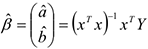 — матричная форма записи
— матричная форма записи
Теорема Гаусса-Маркова
Основная теорема линейной регрессии.
Пусть есть и выборки объема .
1) 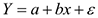
2) 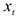 — детерминированное (т.е. случайная величина)
— детерминированное (т.е. случайная величина)
3) a) 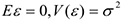
б) или 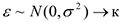 нормальной линейной регрессии
нормальной линейной регрессии
Оценки 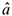 и
и 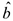 получены методом наименьших квадратов, являются лучшими в классе линейных несмещенных оценок, т.к. обладают наименьшей дисперсией.
получены методом наименьших квадратов, являются лучшими в классе линейных несмещенных оценок, т.к. обладают наименьшей дисперсией.
Замечание: наши оценки являются наилучшими, если мы оцениваем модель, линейную по параметру.
Пример:
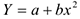 — линейная модель, т.к.
— линейная модель, т.к. 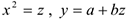 или
или 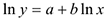 — линейная модель по параметру
— линейная модель по параметру 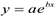 — нелинейная модель
— нелинейная модель
Замечание: остатки после построения регрессии должны иметь нормальное распределение с параметрами математическое ожидание=0 и диспсрсия=0, т.е., оценив регрессию, мы должны проверить остатки на нормальность.
Оценив параметры модели, мы хотим узнать, насколько точно мы оценим коэффициент. Точность оценки связана с ее дисперсией.
Поэтому найдем дисперсию и . Для простоты расчетов введем обозначения:
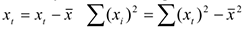
Тогда дисперсия оценки будет равна:
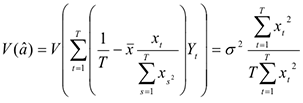

Теперь у нас есть наилучшие оценки коэффициентов регрессии и , однако в регрессионном уравнении есть еще один неизвестный параметр — это дисперсия ошибок 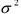 .
.
Из этих двух формул следует, что чем больше измерений, тем точнее результат и меньше дисперсии.
Рассмотрим дисперсию ошибок более подробно. Обозначим через
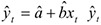 — прогноз в точке
— прогноз в точке 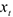
Тогда остатки моделей 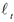 будут собой представлять разницу между истинными и прогнозируемыми значениями.
будут собой представлять разницу между истинными и прогнозируемыми значениями.
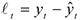
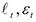 — случайные величины, но — остатки,
— случайные величины, но — остатки, 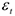 — ошибки Но остатки в отличие от ошибок ненаблюдаемы, поэтому для оценки дисперсии ошибок проще рассмотреть ее через остатки.
— ошибки Но остатки в отличие от ошибок ненаблюдаемы, поэтому для оценки дисперсии ошибок проще рассмотреть ее через остатки.
Попробуем выразить дисперсию ошибок через остатки модели.
Поскольку математическое ожидание у ошибок и остатков нулевое, то дисперсия выражается через математическое ожидание суммы:
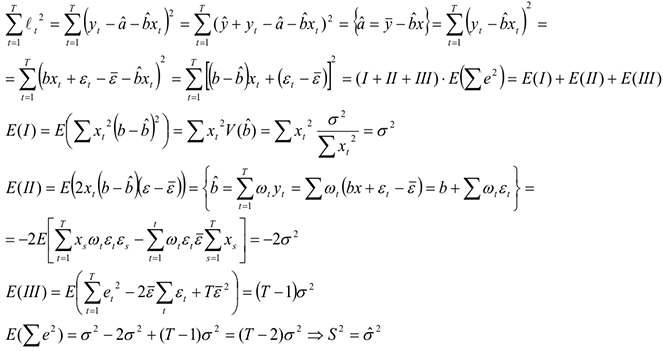
— неизвестная дисперсия остатков
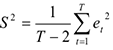
Замечание: неизвестная дисперсия остатка связана с количеством наблюдений (их должно быть как можно больше) и с ошибками (они должны быть как можно меньше). Поэтому из двух подобранных моделей мы выбираем ту, которая точнее строит прогнозы даже если она построена по выборке объемом с меньшим .
Ковариационная матрица
Симметричная диагональная матрица, на диагонали у которой стоят дисперсии; 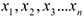 выборки объема .
выборки объема .
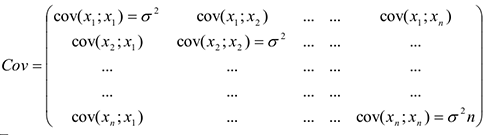
Также можно построить корреляционную матрицу, на диагонали которой 1 — диагональная симметричная матрица, у которой остальные элементы — это соответствующие коэффициенты корреляции, характеризующие силу связи и изменяющиеся от [-1;1]
Замечание: Таким образом, используя корреляционную матрицу для построения регрессии, мы выбираем тот 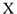 , коррелированность с
, коррелированность с 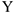 которого по модулю наибольшая, т.е. мы выбираем тот параметр для получения наилучших результатов, сила связи которого с наибольшая, т.е. коэффициент по модулю наибольший.
которого по модулю наибольшая, т.е. мы выбираем тот параметр для получения наилучших результатов, сила связи которого с наибольшая, т.е. коэффициент по модулю наибольший.
Дисперсионный анализ
Попробуем разложить дисперсию изменчивости явления на две составляющие — объясненную регрессией и необъясненную.
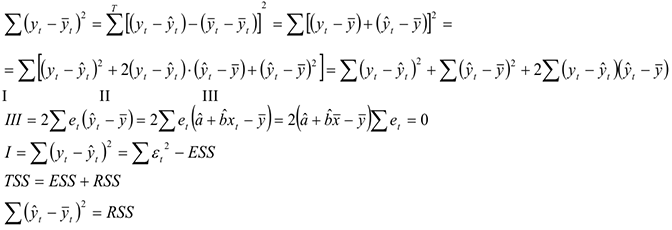
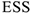 — дисперсия, необъясненная уравнением, та, которая осталась неизвестной в остатке.
— дисперсия, необъясненная уравнением, та, которая осталась неизвестной в остатке. 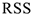 — та часть дисперсии, которая объяснена регрессионным уравнением. На основании этого вводится
— та часть дисперсии, которая объяснена регрессионным уравнением. На основании этого вводится 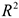 — коэффициент детерминации, характеризующий долю объясненной дисперсии с помощью данного регрессионного уравнения в общей дисперсии.
— коэффициент детерминации, характеризующий долю объясненной дисперсии с помощью данного регрессионного уравнения в общей дисперсии.
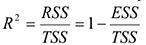
Этот коэффициент используется для выбора наилучшей модели из множества построенных.
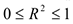
Если = О, то мы ничего не объяснили с помощью построенной регрессии Если = 1, то мы учли всю изменчивость признака. Из двух моделей выбирается та, у которой:
1) все коэффициенты значимы 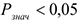
2) максимально простая (т.е. как можно меньше параметров)
3) как можно больше
4) экономическая интерпретируемость коэффициентов (объясняемость)
5) как можно более точный прогноз (при работе с выборкой отсекаются 5-10 значений, на которые и строится прогноз)
Модель множественной регрессии
Обобщением двумерной или парной линейной регрессии служит многомерная линейная регрессия
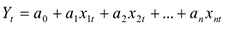
уравнение многомерной линейной регрессии.
где
Основные гипотезы:
1) 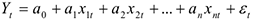 спецификация модели — вид, линейный по параметрам
спецификация модели — вид, линейный по параметрам
2) 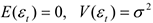 — не зависит от
— не зависит от 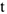
3) 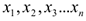 независимые параметры;
независимые параметры; 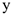 — зависимый
— зависимый
4) 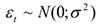
Запишем это уравнение в матричной форме
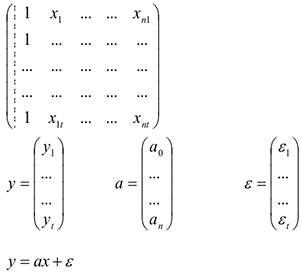
Построить такое уравнение регрессии означает найти оценку параметра, т.е. оценку вектора а.
По теореме Маркова-Гаусса если выполняются основные гипотезы 1,2,3,4, то можно применить
метод наименьших квадратов, с помощью которого получится следующее уравнение:
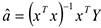 , где
, где 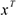 — икс транспонированный
— икс транспонированный
Т.к. мы находим оценки коэффициентов, а не их истинное значение, то нам хотелось бы оценить точность оценивания.
Она связана с вариацией оценки, т.е. с дисперсией: чем больше дисперсия, тем меньше точность и больше вариация. Тогда:
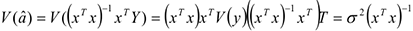
Используя правила перемножения матриц, получаем:
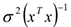
Замечание: из формулы (**) видно, что чем больше параметров, тем больше дисперсия. Поэтому мы выбираем максимально простую модель.
Оценивание качества многомерной линейной регрессии осуществляется так же, как и двумерной, но следует помнить, что 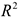 растет с увеличением параметров, поэтому с помощью можно сравнивать только модели с одинаковым количеством зависимых параметров.
растет с увеличением параметров, поэтому с помощью можно сравнивать только модели с одинаковым количеством зависимых параметров.
Спецификация модели
Под спецификацией понимают выбор параметров регрессии 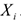 . Т.к. на практике исследуется приближенная модель, рассмотрим соотношение между МНК-оценками параметров выбранной и истинной модели. Рассмотрим два случая:
. Т.к. на практике исследуется приближенная модель, рассмотрим соотношение между МНК-оценками параметров выбранной и истинной модели. Рассмотрим два случая:
1) Исключение. В модель не включали существенные параметры. Тогда оценивается модель, где 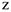 — часть существенных параметров. Мы оцениваем
— часть существенных параметров. Мы оцениваем 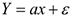
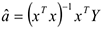
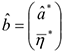
истинная оценка.
Найдем математическое ожидание полученной оценки
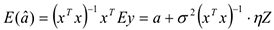
Получаем смещенные оценки, т.е. оценка не такая хорошая, но можно показать, что се дисперсия
будет меньше.
2) Включение в модель несущественных параметров.
Пусть истинная модель: 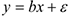 , а оценивается модель:
, а оценивается модель: 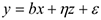 Выписывая оценку коэффициентов
Выписывая оценку коэффициентов 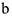 в оцениваемой модели, можно показать, что
в оцениваемой модели, можно показать, что
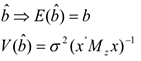
оценка несмещенная, но дисперсия
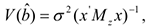
где 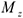 — матрица, зависящая от , т.е. оценка несмещенная, но дисперсия оценки увеличивается от включения в модель несущественных параметров. Следствие: выбирая из двух зол наименьшее, лучше не включать часть существенных параметров, чем включить несущественные.
— матрица, зависящая от , т.е. оценка несмещенная, но дисперсия оценки увеличивается от включения в модель несущественных параметров. Следствие: выбирая из двух зол наименьшее, лучше не включать часть существенных параметров, чем включить несущественные.
Dummy — переменные, фиктивные переменные
Как правило, независимые переменные в регрессионных моделях имеют непрерывные области распределения. Однако некоторые переменные могут иметь всего два или дискретное множество значений, например: пол, уровень образования, рейтинг, оценка и т.д.
Например: рассмотрим в качестве зависимой переменной 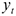 — заработная плата, а
— заработная плата, а 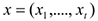 -набор объясняющих переменных.
-набор объясняющих переменных.
Хотим в модель включить новую бинарную переменную, отвечающую за наличие или отсутствие высшего образования. Тогда необходимо включить в модель новую переменную , если 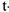 -ый рабочий имеет высшее образование;
-ый рабочий имеет высшее образование; 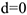 , если не имеет)
, если не имеет)
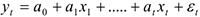
и рассмотреть новую модель
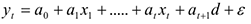
Тогда средняя заработная плата для людей без высшего образования = 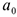 с высшим образованием =
с высшим образованием = 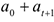
Т.е. коэффициент 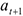 интерпретируется как среднее изменение з/п при переходе из одной категории в другую при неизменных остальных параметрах. Т.е. люди с высшим образованием получают на рублей больше. Если коэффициент перед
интерпретируется как среднее изменение з/п при переходе из одной категории в другую при неизменных остальных параметрах. Т.е. люди с высшим образованием получают на рублей больше. Если коэффициент перед 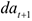 незначим, т.е. его
незначим, т.е. его 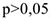 , то различий в з/п между категориями нет.
, то различий в з/п между категориями нет.
Замечание: качественное различие можно формализовать с помощью любой переменной, принимающей два значения, а не обязательно 0 и 1. Но тогда интегрируемость коэффициента усложняется.
Замечание: если включающаяся в модель dummy переменная имеет не два, а несколько значений, то в принципе можно было бы ввести дискретную переменную, принимающую такое же количество значений, но тогда, во-первых, затрудняется интерпретация, во-вторых, подразумевается одинаковое различие между состояниями признака. Поэтому вводят несколько бинарных переменных.
Пример оформления заказа №1.
пусть оценивается стоимость мобильного телефона. В качестве дискретного признака выступает вид телефона:

Вводятся 4 бинарных переменных

Мы не включили в модель 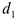 , т.к. тогда для любой строки выполнялось бы
, т.к. тогда для любой строки выполнялось бы 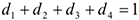 , т.е. регрессоры были бы линейно зависимы, т.е. мы не смогли бы получить МНК-оцснку параметров, т.к. не смогли бы обратить матрицу. Интерпретация коэффициентов:
, т.е. регрессоры были бы линейно зависимы, т.е. мы не смогли бы получить МНК-оцснку параметров, т.к. не смогли бы обратить матрицу. Интерпретация коэффициентов:
Средняя стоимость телефона слим: 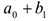 , раскладушка:
, раскладушка: 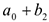 , вертушка:
, вертушка: 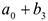
Замечание: если рассматривается ситуация, когда бинарная переменная описывает не всевозможные варианты, то в модель включаются все переменные.
Пример оформления заказа №2.
если рассматривается вторичный рынок квартир в Москве, то зависимая переменная -это стоимость 1 кв.м. В качестве одного из факторов используют количество комнат и включают в модель 4 новые переменные следующего вида:

В модель включаются все 4 переменные, т.к. в базе данных по квартирам присутствуют и многокомнатные квартиры, т.е. больше четырех комнат.
Прогнозирование
После построения регрессионного уравнения и оценки значимости ее коэффициентов, можно получить предсказанное значение результата 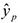 с помощью точного прогноза при заданном значении фактора
с помощью точного прогноза при заданном значении фактора 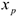 . Для этого в полученное уравнение регрессии
. Для этого в полученное уравнение регрессии 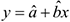 надо подставить факторы , после чего получить прогноз. Это так называемый точечный прогноз, но он не даст требуемых представлений, и мало применим на практике. Поэтому дополнительно необходимо осуществить определение стандартной ошибки прогнозирования
надо подставить факторы , после чего получить прогноз. Это так называемый точечный прогноз, но он не даст требуемых представлений, и мало применим на практике. Поэтому дополнительно необходимо осуществить определение стандартной ошибки прогнозирования 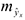 и получить интервальную оценку прогнозного значения.
и получить интервальную оценку прогнозного значения.
Чтобы построить интервальный прогноз, необходимо найти верхнюю и нижнюю границы. Найдем сначала формулу стандартной ошибки прогнозирования . Вставим в формулу линейной регрессии значение параметра . Тогда уравнение регрессии имеет следующий вид:
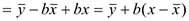
Из этой формулы следует, что стандартная ошибка прогнозирования зависит от ошибки 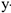 -среднее и ошибки коэффициента регрессии
-среднее и ошибки коэффициента регрессии 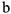 . Тогда
. Тогда
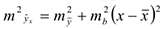
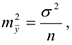
если 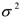 — неизвестна, то ее заменяют на оценку дисперсии
— неизвестна, то ее заменяют на оценку дисперсии 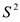
Учитывая ошибку регрессии 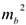 , получаем следующую формулу для прогноза:
, получаем следующую формулу для прогноза:
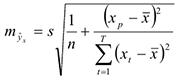
Тогда интервальный прогноз или доверительный интервал прогнозируемого значения рассчитывается следующим образом:
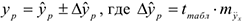 -предельная ошибка прогноза
-предельная ошибка прогноза
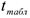 — кванти с уровнем доверия
— кванти с уровнем доверия 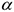
Например: =0,95, то истинное значение попадет в доверительный интервал 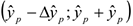 с вероятностью 0,95
с вероятностью 0,95
Строя прогноз, мы хотим получить как можно более точный прогноз и как можно меньший интервал (узкий), но чем выше , тем дальше друг от друга границы интервала и наоборот. Поэтому приходится искать компромисс. Часто в задачах задано заказчиками исследования. Поэтому, строя модель, мы должны помнить, что хорошая модель — это та, интервальные прогнозы, по которой достаточно точные и границы не слишком далеко друг от друга, а сам интервал неширокий.
Замечание: если построенная по выборке модель имеет высокий 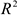 , все оценки значимы, остатки близки к нормальным, но прогнозы неточные, широкие интервалы прогнозирования (плохая прогностическая способность модели), то, возможно, вы просто подогнали модель под данные и она не подходит, т.е. ее надо переделать, т.е. прогнозирование можно использовать в качестве оценки качества модели.
, все оценки значимы, остатки близки к нормальным, но прогнозы неточные, широкие интервалы прогнозирования (плохая прогностическая способность модели), то, возможно, вы просто подогнали модель под данные и она не подходит, т.е. ее надо переделать, т.е. прогнозирование можно использовать в качестве оценки качества модели.
Выбор параметров линейной регрессии (процедура пошагового отбора)
При построении регрессии для подбора наиболее подходящих параметров используется либо метод включений, либо метод исключений. Смысл метода включений:
1) По матрице корреляций выбирается параметр, коэффициент корреляции которого с зависимой переменной (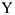 ) — наибольший
) — наибольший
2) Строится парная регрессия на этот параметра 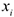 .
.
3) Если коэффициент линейной регрессии значим, т.е. 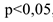 , то параметр остается а
, то параметр остается а
4) Берется следующий параметр.
5) Строится регрессия 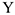 на
на 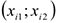 Оценивается значимость коэффициентов.
Оценивается значимость коэффициентов.
Если коэффициент при соответствующем параметре незначим, параметр исключают 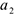 . Если не значим — смотри пункт 4)
. Если не значим — смотри пункт 4)
7) После рассмотрения последнего параметра должна получиться многомерная регрессия, у которой вес параметры значимы.
8) Рассматриваем более детально не вошедшие в модель параметры и пытаемся определить, с чем связано их не влияние: либо неудачная выборка, либо неправильно определен параметр, либо не включенные параметры влияют только во взаимодействии с другими параметрами.
Смысл метода исключений:
1) Строим регрессию 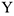 на все параметры
на все параметры 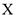
2) Исключаем самый незначимый параметр.
3) Строим новую регрессию
По окончании процедуры должна получиться регрессия 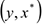 где все параметры значимы.
где все параметры значимы.
Рассмотрим более детально не вошедшие в модель параметры. Выбросы — в экономике ими называются резко отличающиеся от других значения, цена.
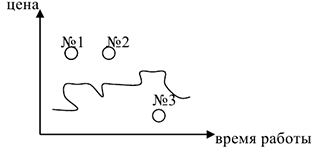
Если рассматривать мобильные телефоны, зависимость цены от времени работы, то №1, №2, №3 считаются выбросами, т.к. №1 и №2 имеют слишком большую цену, а у №3 при самом большом времени работы самая маленькая цена.
5%-10% от выборки.
Встает проблема определения выбросов.
Существует множество процедур определения выбросов. Рассмотрим один из них. Рассмотрим зависимость от параметров
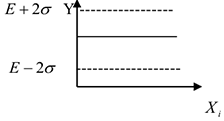
Для определения того, является ли значение выбросом или нет, используют следующее: строят интервал следующего вида: математическое ожидание параметра 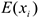 минус два стандартных отклонения
минус два стандартных отклонения 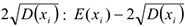 -левая граница
-левая граница
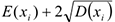 -правая граница
-правая граница
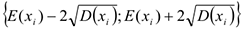
Те значения параметра, которые не попадут в этот интервал, считаются выбросами. Если при построении регрессии параметров несколько, то сначала по каждому из параметров определяются номера выбросов, а затем либо все они считаются выбросами, либо только наиболее часто встречаемые номера.
Обязательное условие этой процедуры — это пояснение, почему то или иное наблюдение является выбросом.
Работа с процедурными значениями
При работе с финансовыми показателями и макроэкономическими показателями часто встречается ситуация, когда часть значений отсутствует.
Например: по одному из регионов России отсутствует значение одного из параметров. В этом случае возможны два варианта:
1) Исключить наблюдения, в которых есть пропущенные значения. Но в ряде случаев выборка небольшая или слишком много значений, и тогда первый вариант не подходит.
2) Восстановление пропущенных значений, т.е. неизвестное значение заменяется возможным подходящим:
а) ставится среднее
б) нулевое
в) по аналогии с похожим наблюдением
г) используется метод линейной аппроксимации.
Вопрос о заполнении пропущенных значений при работе с реальными данными встречается довольно часто. До сих пор этот вопрос не решен окончательно.
Общая методика построения регрессионного уравнения
1) Выбираем зависимую переменную 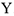 .
.
2) Рассматриваем парные графики зависимостей от 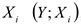 , где
, где 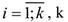 — параметр.
— параметр.

По виду этого графика делаются выводы о наличии или отсутствии зависимости и о виде этой зависимости.
3) Рассматривается матрица корреляции между зависимой переменной и независимой.
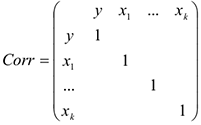
Интерпретируются знаки линейной корреляции и сила линейной связи. Если 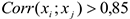 , то один из них исключается
, то один из них исключается
4) С помощью метода пошагового отбора строим регрессию 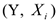
5) Подбираем спецификацию модели, а именно максимизируя 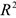 , минимизируется количество параметров линейной регрессии.
, минимизируется количество параметров линейной регрессии.
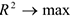 , количество параметров регрессии
, количество параметров регрессии 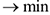
Подбирая спецификацию модели можно использовать следующие соображения:
а) 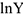 , тогда зависимая переменная не уйдет в минус и зависимость
, тогда зависимая переменная не уйдет в минус и зависимость 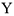 от постепенно, т.е. при изменении параметра на 1, меняется в процентах.
от постепенно, т.е. при изменении параметра на 1, меняется в процентах.
6) берется параметр в квадрате, если с увеличением его влияние на возрастает.
в) 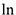 параметра. В этом случае с ростом значения параметра, влияние на уменьшается.
параметра. В этом случае с ростом значения параметра, влияние на уменьшается.
г) использование взаимодействия параметров, например их перемножение.
б) Построение прогноза (точного) наилучшей подобранной модели
7) Построение интервального прогноза, т.е. построение — 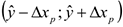
8) (Дополнительно) Работа с выбросами. После их удаления п.4-п.7 и сравниваются.
9) Интерпретация полученных результатов:
а) описание экономического смысла модели
б) интерпретация коэффициентов и знаков перед ними
в) анализ точности прогнозирования и ширины интервала
г) описание выбросов
Анализ силы связи порядковых и категориальных переменных
Количественные (или номинальные) переменные — переменные, выражающиеся в числах в определенных единицах измерения.
Категориальные переменные — это переменные, принимающие конечное число значений, состоящих из категорий, которые неупорядочены относительно друг друга. Чаще всего выражаются не в числах.
Например: цвет, уровень образования, страна, фамилия.
Порядковые переменные — это категориальные переменные, для которых определено отношение порядка, т.е. они ранжированы относительно друг друга.
Например: оценка успеваемости, номер места на соревнованиях или группы людей по возрастам. В исследовании социально-экономических явлений часто возникает необходимость оценить силу связи между категориальными и порядковыми переменными. Коэффициент корреляции Пирсона, который считали ранее, не подходит, он не показывает реального состояния. Необходимо использовать другие коэффициенты связи.
Пример оформления заказа №3.
Пусть у нас имеется лекарство и мы хотим проверить есть ли связь между приемом этого лекарства и состояния больного.
Всех больных случайным образом делят на 2 группы. 1-ю группу лечат новым препаратом, а 2-ю группу лечат традиционными методами. Таким образом мы получаем 2 показателя: 1-ый показатель: проходил ли больной курс лечения новым препаратом. 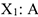 — давали лекарство
— давали лекарство
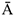 — не давали
— не давали 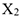 — результат лечения.
— результат лечения. 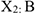 — состояние улучшилось
— состояние улучшилось 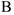 — состояние ухудшилось Результаты этого опыта можно представить в таблице,
— состояние ухудшилось Результаты этого опыта можно представить в таблице, 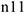 — число людей, которым давали лекарство и чье состояние улучшилось.
— число людей, которым давали лекарство и чье состояние улучшилось. 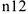 — число людей, которым давали лекарство и чье состояние ухудшилось.
— число людей, которым давали лекарство и чье состояние ухудшилось.
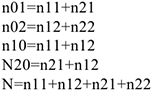
Задача состоит в том, чтобы по этим 4-м числам определить, связан ли результат лечения с приемом лекарства и как именно связан. Рассмотрим разные варианты.
1.Если между 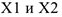 нет никакой связи, лекарство бессмысленно. Тогда доля принимавших лекарство среди больных, чье состояние улучшилось должна быть равна доле принимавших лекарство среди тех, кому стало хуже и равна доле принимавших лекарство среди всех больных.
нет никакой связи, лекарство бессмысленно. Тогда доля принимавших лекарство среди больных, чье состояние улучшилось должна быть равна доле принимавших лекарство среди тех, кому стало хуже и равна доле принимавших лекарство среди всех больных.
Доля принимающих лекарство, чье состояние улучшилось=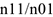 Доля принимающих лекарство, чье состояние ухудшилось=
Доля принимающих лекарство, чье состояние ухудшилось=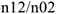
Доля принимавших лекарство среди всех участвующих в эксперименте=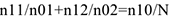
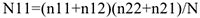 — то связи нет!
— то связи нет!
На равенстве долей и построена мера связи. За меру связи можно принять величину 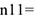 …, но у этой величины значения могут быть и больше 1 и меньше 1 по модулю=> ее необходимо модифицировать, чтобы сделать похожей на коэффициент корреляции. А именно ввести коэффициент Юла, равный
…, но у этой величины значения могут быть и больше 1 и меньше 1 по модулю=> ее необходимо модифицировать, чтобы сделать похожей на коэффициент корреляции. А именно ввести коэффициент Юла, равный
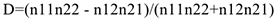
Если 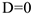 , то связи нет.
, то связи нет.
Если связь сильная отрицательная, то коэффициент Юла 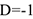 Если связь сильная положительная, то
Если связь сильная положительная, то 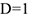
Замечание: Коэффициент Юла подходит, если рассматривается таблица 2*2. Т.е. определяется сила связи между 2-мя параметрами, каждый из которых принимает только 2 значения. Связь считается подтвержденной, если 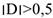 .
.
Пример 1.
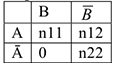
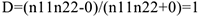
т.е. из нелечения =>ухудшение состояния.
Пример 2.

т.е. из лечения =>ухудшение самочувствия или если не лечили, то обязательно стало лучше.
Однако часто в маркетинговых исследованиях приходится сталкиваться с ситуацией, когда 1 или оба признака принимают несколько значений.
В этом случае рассчитать коэффициент Юла не получится и следует использовать другие коэффициенты.
Примером таблиц 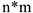 может служить анализ результатов выборок кандидатов в разных регионах. Тогда каждому региону сопоставляют столбец, а каждому кандидату — строку.
может служить анализ результатов выборок кандидатов в разных регионах. Тогда каждому региону сопоставляют столбец, а каждому кандидату — строку.

В таблице стоят значения рейтинга кандидата в соответствующем регионе. Требуется установить связь между регионом и рейтингом в нем кандидатов. Рассмотрим различия статистики тесноты связи: 1. Фи — коэффициент. Его используют для таблиц 2*2.
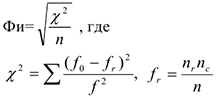
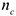 — итоговое число в столбце
— итоговое число в столбце
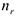 — итоговое число в строке
— итоговое число в строке
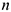 — полный размер выборки
— полный размер выборки
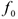 — соответствующее число в таблице
— соответствующее число в таблице
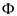 — коэффициент принимающий значение, равное 0, если связь присутствует, и 1, если связь сильная.
— коэффициент принимающий значение, равное 0, если связь присутствует, и 1, если связь сильная.
Пример оформления заказа №4.
Найти связь между использованием Интернета и полом.


Тогда
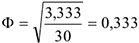
Таким образом связь положительная, не очень сильная.
применяется только для таблиц 2*2, а коэффициент сопряженности С используется в таблице любого размера.
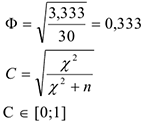
Также используется 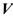 — коэффициент Крамера, который является модификацией. Для таблиц с
— коэффициент Крамера, который является модификацией. Для таблиц с 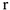 рядами
рядами
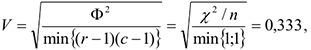
— коэффициент подтверждает наличие слабой связи.
Коэффициент взаимной сопряженности Чупрова
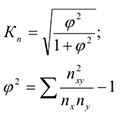
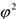 — коэффициент взаимной сопряженности. Чем ближе Кп к 1, тем теснее связь.
— коэффициент взаимной сопряженности. Чем ближе Кп к 1, тем теснее связь.
Пример оформления заказа №5.


Оценить взаимосвязь между уровнем жизни респондента и формой собственности предприятий, на которых они работают.
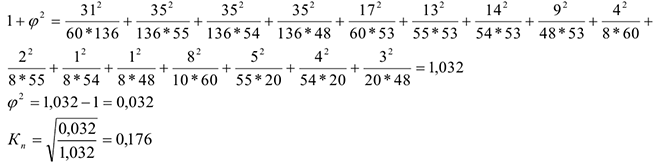
Вывод: коэффициент маленький (меньше 0,3) => значимой связи между формой собственности и уровнем жизни.
Существует модификация этого коэффициента через 
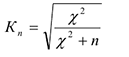
Биссериальный коэффициент корреляции
Он имеет особое значение, т.к. позволяет оценить связь между качественным альтернативным и количественным варьирующим признаком.
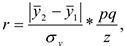
где
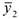 и
и 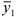 — средние по группе
— средние по группе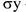 — корень из дисперсии (для количественной переменной)
— корень из дисперсии (для количественной переменной) 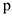 — доля 1 -ой группы
— доля 1 -ой группы 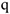 — доля 2-ой группы
— доля 2-ой группы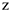 — табличное значение в зависимости от распределения значений 1-ой группы.
— табличное значение в зависимости от распределения значений 1-ой группы.
Пример оформления заказа №6.
Найти зависимость между возрастом и социальным положением потенциальных эмигрантов.
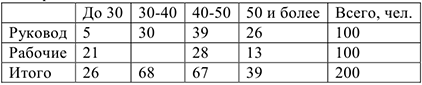
Оценить силу связи
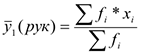
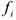 — частота проявления признаков.
— частота проявления признаков.
Выбираем среднее в группе = [255+3530+4539+5526]* 1/100=43,6 Средний возраст эмигрантов — руководителей =43,6 лет.
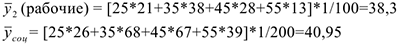
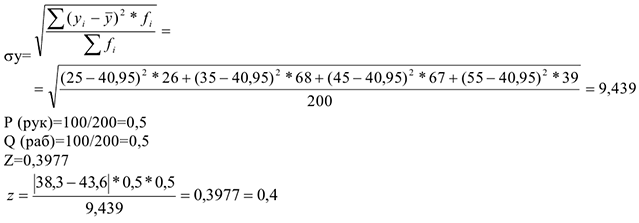
Ранговые коэффициенты корреляции
Как определить силу линейной связи между порядковыми переменными, между которыми существует отношение упорядоченности, т.е. между ранжированными значениями? Все дальнейшие рассуждения опираются на понятие ранг. Ранг — номер объекта в упорядоченном ряду.
Например: эксперт сравнивает объекты и выстраивает их по порядку. Чем лучше объект, тем выше ранг ему присваивают.
 — ранжированный вариационный ряд
— ранжированный вариационный ряд
ранг
 — объем выборки.
— объем выборки.
К сожалению, бывает, что ранги не различимы. Если же какие-то объекты не различимы для объекта, то используется понятие распределенный ранг. Тогда всем 3-м объектам присваивается один и тот же номер ранга, получаемый как сумма рангов этих объектов, деленная на их количество.
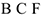 — не различимы
— не различимы
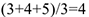
Суммарное значение всех присвоенных рангов зависит от объема выборки и может быть рассчитан следующим образом:
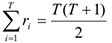
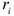 — номер ранга, присвоенного
— номер ранга, присвоенного 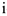 -му объекту.
-му объекту.
В нашем случае
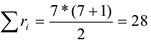
Коэффициент корреляции Спирмена
Рассмотрим задачу о силе связи 2-х различных оценок. Эти 2 оценки были получены с помощью оценивания одного и того же множества, но разными критериями. Например: инвестиционные проекты могут быть оценены с помощью или чистого дохода или срока окупаемости.  — 1-ый признак
— 1-ый признак  — 2-й признак.
— 2-й признак.
Тогда результаты оценивания могут быть представлены в таблице.

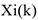 — это значение ранга, присвоенного объекту с номером к по -му признаку. В нашем случае
— это значение ранга, присвоенного объекту с номером к по -му признаку. В нашем случае 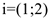
Требуется определить силу связи этих 2-х оценок, причем желательно, чтобы мера связи лежала в отр. [-1;1] и была бы равна
0, если связи нет
1, если связь сильная положительная -1, если связь сильная отрицательная
Связь будет идеально положительна, если
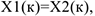
т.е. совпадают.
Связь будет сильно отрицательной, если 2-й ряд упорядочен в обратном порядке, т.е. 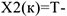
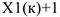
В качестве меры связи можно использовать ранговый коэффициент корреляции Спирмена, который для 2-х критериев выглядит следующим образом: 6 т
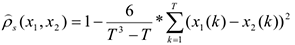
Если имеются распределительные ранги, то выражение сильно усложняется. Пример.
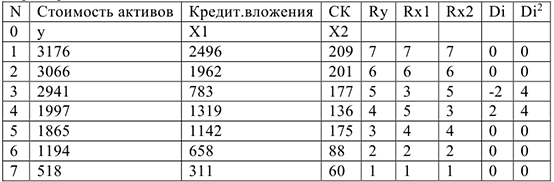
Тогда коэффициент корреляции Спирмена
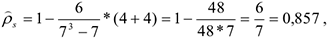
Т.е. связь очень сильная положительная.
Много активов у банка, у которых много кредитов.
Использование эконометрических методов в маркетинговых исследованиях
Процесс маркетинговых исследований состоит из 6 этапов:
- Определение проблемы. На этом этапе выявляется основная проблема и какая информация нужна для решения данной задачи.
- Разработка подхода к решению проблемы. На этом этапе формируются рамки исследования, аналитические модели, план исследования, собираются необходимые вторичные данные.
- Разработка плана исследования. План маркетингового исследования детализирует ход выполнения процедур, необходимых для получения нужной информации, т.е. определяется, каким образом получаются данные от респондентов, шкалы измерения. На этом этапе активно привлекают социологов и психологов.
- Полевые работы или сбор данных.
- Подготовка данных и их анализ. Подготовка данных включает в себя редактирование, кодирование, расшифровку и проверку данных. Каждому ответу присваиваются числовые или буквенные коды. Затем все анкетные данные вводятся в компьютер.
- Подготовка отчета и его презентация. Ход и результат исследования должны быть изложены в форме отчета, полученные выводы должны быть представлены в письменном виде и изложены простым и понятным языком. После определения набора информации, которая должна
быть получена, следует особое внимание уделить формированию выборки, а именно: с учетом доступных времени людей и денег определить: а) размер выборки б) способ ее получения. 7. Кодирование вопросов. Оно заключается в переводе ответов на вопросы в числа.
Например: 1. Действителен ли сегодня ваш паспорт? 1. Да 2. Нет (2/54) 54 — количество человек, выбравших данный ответ
Для проверки получаемой информации и получения первичных результатов анализа используется теория проверки гипотез.
Общая схема проверки гипотез
- Формулировка проверки гипотез. Формируется нулевая гипотеза
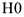 и альтернативная —
и альтернативная — 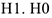 — предположение о том, что между определенными статистическими параметрами не существует связи или различия. Ее подтверждение не требует от компании каких-либо действий.
— предположение о том, что между определенными статистическими параметрами не существует связи или различия. Ее подтверждение не требует от компании каких-либо действий. 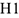 — противоположная гипотеза, т.е. предположение о том, что связь или различие существует. Ее подтверждение означает, что компания должна предпринять какие-либо меры или поменять свои взгляды на положение дел. Маркетолог проверяет всегда нулевую гипотезу.
— противоположная гипотеза, т.е. предположение о том, что связь или различие существует. Ее подтверждение означает, что компания должна предпринять какие-либо меры или поменять свои взгляды на положение дел. Маркетолог проверяет всегда нулевую гипотезу. - Выбор уровня значимости и метода проверки гипотезы. Используют математико-статистический анализ, поэтому то или иное утверждение принимается или отвергается с вероятностью а. Реультатом проверки гипотез является 1 из 2-х вариантов. 1. — принимается
- — отвергается => с вероятностью
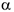 принимается
принимается 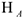 . Например. Руководство универмага хотело бы начать торговлю своими товарами через Интернет. Новая услуга будет введена, если свыше 40% пользователей Интернет используют сеть для совершения покупок. Маркетолог записывает гипотезы следующим образом:
. Например. Руководство универмага хотело бы начать торговлю своими товарами через Интернет. Новая услуга будет введена, если свыше 40% пользователей Интернет используют сеть для совершения покупок. Маркетолог записывает гипотезы следующим образом: 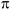 — доля пользователей Интернет, которая совершает покупки меньше
— доля пользователей Интернет, которая совершает покупки меньше
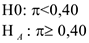
В таких условиях — уровень значимости. =0,95 (0,98)
Если принимается , то услугу внедрять не стоит. Если же не принимается, т.е. нет достаточных оснований принять , тогда принимаем и компания внедряет новую услугу. Еще 1 метод маркетинговых исследований — это использование таблиц сопряженности. Ими часто пользуются, т.к.: 1.Просты в использовании 2.Легко трактуются результаты З.В ряде случаев это очевиднее, чем многоуровневый анализ. 4.Проще работать с пропущенными значениями. 5.Не требует специальных навыков и программ.
Мы рассматривали двумерную кросстабуляцию, т.е. оценивали взаимосвязь 2-х переменных. Тем не менее часто введение 3-й переменной позволяет маркетологу лучше понять природу исходных связей между 2-мя переменными. Введение 3-й переменной может привести к следующему результату:
- Уточнить связь между 2-мя исходными переменными.
- Указать на отсутствие связи, хотя первоначально связь наблюдалось. Т.е. 3-я переменная покажет наличие ложной связи.
- Показать некоторую связь между 2-мя переменными, хотя изначально она не наблюдалась, т.е. покажется скрытая связь.
- Никаких изменений в исходной структуре не будет.
Влияние
Две исходные переменные:
- Есть связь между 2-мя переменными => введение 3-ей => 1.Уточняется связь
2.0тсутстуст связь 3.Исходная структура без изменения
- Отсутствие связи между 2-мя исходными переменными => введение 3-ей => 1.Есть связь между 2-мя исходными переменными 2.Исходящая структура без изменения
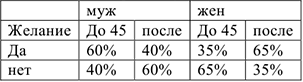
Например. Связь между желанием совершить тур поездку от возраста. Таблица сопряженности 2-х переменных
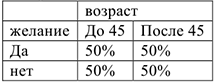
Добавим 3-ю переменную — пол. Можно увидеть подавленную связь между переменными
Структура международных маркетинговых исследований
Провести международное маркетинговое исследование гораздо сложнее, чем исследование внутри страны, т.к. необходимо принимать во внимание факторы внешней и внутренней среды.
- Маркетинговая среда (ценовая политика, инфляционная политика, наличие или отсутствие товара).
- Государство и правительство (т.е. политический строй, протекционистская политика -пошлин, акцизов, дотаций; налоговая и финансовая политика и т.д.)
- Правовая срсда (т.е. право, законодательство, международное право, антимонопольное законодательство).
- Экономическая среда — т.е. уровень и структура ВВП, уровень и структура национального дохода, объем теневой экономики
- Инфраструктура: транспорт, коммуникации, коммуникативные услуги.
- Информационная и технологическая срсда
- Социокультурная среда
Вывод. При использовании экономстрических моделей необходимо обязательно учитывать все эти факторы для получения точных прогнозов, достоверных результатов и применимых моделей.
Временные ряды
Изучение большинства экономических явлений базируется на исследовании свойств некоторой функции от времени 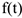 , где
, где 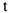 — время. Эта функция определяет развитие явления во времени. — некий процесс, характеризующий развитие явления во времени. Например это инфляция, доходы предприятия, уровень цен, курсы валют и котировки ценных бумаг.
— время. Эта функция определяет развитие явления во времени. — некий процесс, характеризующий развитие явления во времени. Например это инфляция, доходы предприятия, уровень цен, курсы валют и котировки ценных бумаг.
Временной или динамический ряд
Это ряд наблюдаемых значений изучаемого показателя, расположенных в хронологическом порядке или в порядке возрастания времени. Обозначается: 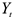 — временной ряд,
— временной ряд, 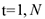 ,
, 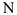 — последняя дата
— последняя дата
Временные данные отличаются от обычных следующим:
- Они не являются статистически независимыми, т.е. наблюдения связаны между собой.
- Временные ряды не являются одинаково распределенными величинами
Классификация временных рядов
- Моментальные — на определенную дату (курс валюты)
- Интервальные — за определенный интервал времени (прибыль предприятий)
- Исходный
- Производственный (прирост цен, прибыль в расчете на численный состав)
Чаще всего работают с исходным рядом, но иногда его преобразуют, получая производственный ряд.
Если значения уровня ряда точно определены какой-либо математической функцией, то такой ряд называется детерминированный или неслучайный.
Если же уровни временного ряда могут быть описаны с помощью функции распределения вероятностей, то такой ряд называется случайным. Временный ряд бывает: — детерминированный (объем, оценка)
- случайный (температура, цена нефти, выборы) Примером детерминированной случайной величины является списочная численность работников. Процессы, которые рассматриваются во времени в соответствии с законами теории вероятности, назы ваются cm охает ическим и.
Особый вид временного ряда — это так называемый белый шум. Это абсолютный теоретический процесс, который реально не существует. Тем не менее, он является очень важной математической моделью, которая широко применяется при решении множества практических задач. Случайная последовательность значений 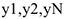 будет белым шумом, если это одинаково распределенные
будет белым шумом, если это одинаково распределенные 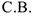 , математическое ожидание которых равно нулю (колеблется около нуля), а дисперсия
, математическое ожидание которых равно нулю (колеблется около нуля), а дисперсия 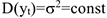 . Белый шум
. Белый шум
Для описания и детального изучения временных рядов используются различные математические модели. Их идентификация предполагает выявление основных компонент, которые содержат изучаемые временные ряды. Данные, представленные виде временного ряда могут содержать 2 компоненты — систематическую и случайную. Систематической компонентой называются факторы, действующие постоянно. Выделяют 3 основных систематических компоненты:
1 .тренд
2.сезонность
3.цикличность
Тренд — линейная или нелинейная компонента, плавно изменяющаяся во времени. Тренд
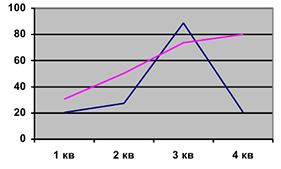
описывает чистое влияние долговременных факторов.
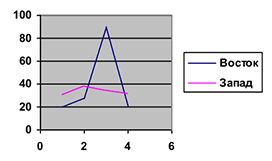
Сезонная компонента — это периодические колебания уровней временного ряда в течение не очень долгого периода. Отражает повторяемость экономических процессов.
Циклическая компонента характеризует длительность повторяющихся фаз явлений. Длительность фаз может быть разной, амплитуда колеблется, но последовательность всегда
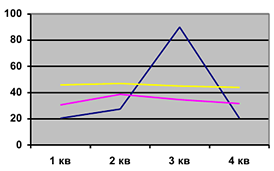
сохраняется.
Разница между соседними периодами или ямами называется периодом цикла.
Например: циклы Кузнецова. Вывел 15-летние строительные циклы инвестиций строительства домов в США.
Случайные составляющие — это случайный шум или ошибка, воздействующая на временной ряд не регулярно. Основными причинами случайных ошибок могут быть факторы резкого и внезапного воздействия, т.е.катастрофы, а также воздействие текущих факторов, которое может быть связано, например, с ошибками наблюдения.
Таким образом, временной ряд может быть представлен как функция 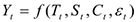 Таким образом модель временного ряда может быть представлена в нескольких вариантах:
Таким образом модель временного ряда может быть представлена в нескольких вариантах:
1 .аддитивная — 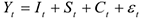
2.мультипликативная — 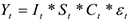
3.смешанная — 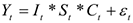
При моделировании на практике часть систематических компонент может отсутствовать. При моделировании временных рядов особое внимание уделяют:
- Прогнозам и доверительным интервалам.
- Восстановлению пропущенных значений, т.к. на практике часто есть сведения не на все даты.
- Анализу зависимости от прошлого
- Виду модели
- Укрупнению значений (т.е. как перейти от ежедневных к ежеквартальным)
- Учет влияния внешних факторов, праздников, выходных.
Замечание: Модель временного ряда считается хорошо подобранной, если после удаления из ряда наблюдаемых значений систематических компонент и моделей зависимости от времени, остатки являются белым шумом (мелкими случайными выбросами, т.е. непрогнозируемый процесс).
Анализ трендовой составляющей
Тренд — основная тенденция или составляющая ряда (она отражает его долговременную тенденцию). Поэтому ее выявление описания очень важно. Для ее определения используют следующие методы:
- Метод механического выравнивания, при котором количественная модель не строится
- Метод аналитического выравнивания — при котором строится Прежде чем определять тренд, необходимо сначала доказать, что он есть.
В наше время известно около 10 методов, позволяющих выявить тренд. Рассмотрим 1 из них.
Метод, основанный на медиане или медианный критерий
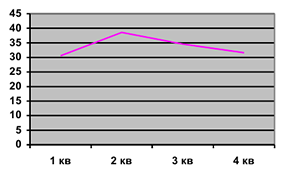
1) Исходный ряд  — ранжируется (по возрасту)
— ранжируется (по возрасту)
2)По ранжированному ряду определяется медиана, т.е.наблюдение, которое делит выборку пополам (50% — выше выборки и 50% ниже)
3)По исходному ряду строится новый ряд, состоящий из 0 и 1.
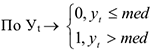
Последовательность 0 или 1 называется серией.
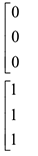
Далее определяется количество серий 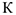 и длина максимальной серии
и длина максимальной серии 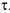 .
.
Считается, что тренд есть, если не выполнено хотя бы 1 из 2-х неравенств:
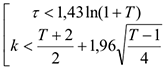
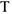 — объем выборки.
— объем выборки.
1,96 — квантиль нормального распределения.
После того, как определили наличие тренда, можно приступить к его моделированию. Метод аналитического выравнивания заключается в том, что трендовая составляющая ищется как функция от времени.
Для оценки точности построения тренда используют значимость коэффициентов и 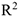 . В практике статистических исследований различают следующие типы развития явления во времени, т.е. следующие типы трендов:
. В практике статистических исследований различают следующие типы развития явления во времени, т.е. следующие типы трендов:
- Равномерное развитие, т.е.развитие с постоянным абсолютным приростом значений уровня ряда.
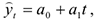
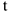 — время
— время
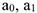 — неизвестные коэффициенты, которые находятся методом наименьших квадратов
— неизвестные коэффициенты, которые находятся методом наименьших квадратов 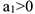 — рост
— рост 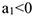 — спад
— спад
- Равноускоренное или равнозамедленнос развитие — это развитие при постоянном увеличении или замедлении темпа прироста уровня ряда
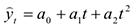
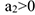 — ускорение развития
— ускорение развития 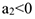 — замедление развития
— замедление развития
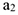 — коэффициент, характеризующий постоянное изменение скорости развития
— коэффициент, характеризующий постоянное изменение скорости развития
- Развитие с переменным ускорением или замедлением.
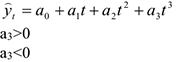
Развитие с замедлением роста в конце периода
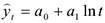
Развитие по экспоненте
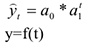
Это развитие явления, характеризуется стабильным темпом роста или снижения, 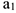 — коэффициент, характеризующий степень интенсивности развития
— коэффициент, характеризующий степень интенсивности развития
- Развитие по степенной функции — это развитие с постоянным относительным приростом уровней степенного ряда.
Используя метод аналитического выравнивания на основании 100 ежедневных данных о курсе евро, можно получить следующее уравнение:
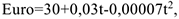
Тогда прогноз на следующий день, полученный с помощью этой модели будет выглядеть следующим образом:
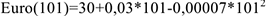
Замечания:1. Для того, чтобы построить уравнение тренда на компьютере, необходимо сначала создать новую переменную:
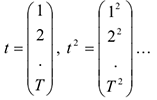
затем строим обычную регрессию, вместо зависимой переменной подставляем новые ряды. Полученные оценки коэффициентов и образуют уравнение регрессии.
- Для того, чтобы с помощью данной методики действительно выявить основную тенденцию, необходим большой объем данных, а именно объем выборки.
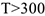 , в противном случае основная тенденция будет выявлена неправильно.
, в противном случае основная тенденция будет выявлена неправильно. - Трсндовая модель в исследуемый период должна развиваться эволюционно, т.е.необходимо учесть резкие всплески, кризисы. Например: структурный сдвиг, который необходимо учитывать.
- При моделировании временных рядов необходимо также учитывать автокорреляцию, т.е.зависимость сегодняшнего от прошлого
- Если подбирая полученную модель получилась очень большая степень тренда (больше 3-4). Возможно имеет место сезонность. Например:
Следует сначала избавиться от сезонности, а потом уже моделировать. 7. При моделировании основной тенденции основным показателем качества модели должен служить экономический смысл, т.е. объясняемость результатов. И только потом учитывать математические характеристики.
Корреляция во времени
При моделировании временных рядов часто приходится учитывать корреляцию во времени, т.е. зависимость от прошлых значений. При моделировании временного ряда с автокорреляцией случайные остатки не будут близки к нормальным. Т.с. не выполнится основное требование теоремы Гаусса-Маркова, т.е. для такой модели полученные оценки коэффициентов не будут стремится к истинным значениям, т.е. прогноз, полученный по такой модели будет слишком оптимистичным.
Для учета зависимости от прошлых значений используют оператор сдвига 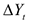
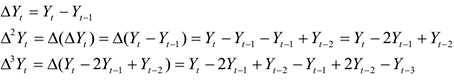
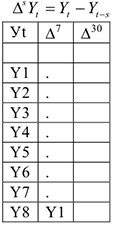
Для того, чтобы найти зависимость между текущим значением и значением на 1 шаг назад по времени, рассматривают коэффициент корреляции между исходным рядом и . Например: ряд выглядит следующим образом:
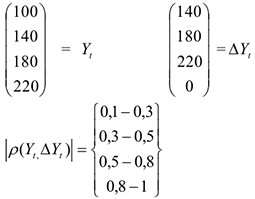
Если необходимо определить связь между текущим значением и значением 2 шага во времени назад, то рассматривается коэффициент корреляции между
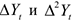
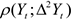
По аналогии находится зависимость от более дальних шагов по времени.
Анализ сезонности во временных рядах
Существует несколько основных методов выделения сезонных и циклических колебаний. К ним относятся:
1 .Расчет сезонной компоненты и построение аддитивной или мультипликативной модели временного ряда. Рассчитывается либо сезонная средняя либо индекс сезонности.
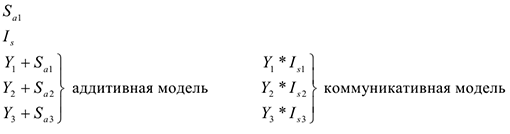
2.Анализ сезонности с помощью автокорреляционной функции.
3.Моделирование с помощью рядов Фурье.
При этом подходе строится зависимость (т.е.регрессионная модель), в которой в качестве характеристик сезонности включается пара sin и cos, характеризующая свои определенные периоды. В данном случае сезонная составляющая представляет собой:
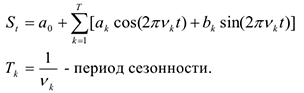
Например. Если 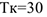 дням, то выявлена ежемесячная сезонность
дням, то выявлена ежемесячная сезонность
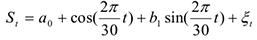
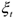 — случайная ошибка
— случайная ошибка
В этой модели неизвестными являются параметры, которые находятся с помощью МНК, но для того, чтобы оценки были близки к истинным значениям, необходимо выполнение тех же условий, что и для модели линейной регрессии, а именно 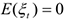
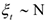 — нормальное распределены.
— нормальное распределены.
Пример оформления заказа №7.
По выборке о динамике урожайности зерновых культур, в одном из частных хозяйств была построена следующая трендовая модель
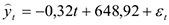
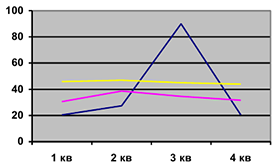
остатки 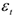 оказались не близки к нормальным и их средняя была далеко от 0. Поскольку график остатков явно содержал сезонные составляющие, то для остатков была построена модель сезонных составляющих с помощью ряда Фурье (Microsoft Excel)
оказались не близки к нормальным и их средняя была далеко от 0. Поскольку график остатков явно содержал сезонные составляющие, то для остатков была построена модель сезонных составляющих с помощью ряда Фурье (Microsoft Excel)
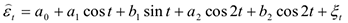
После построения модели оказалось близко к нормальному распределению, а их МО стало близко к 0.
Замечание. Так как большое количество параметров усложняет модель, делает ее сложно применимой и требует большого количества наблюдений, то при анализе сезонности необходимо выбрать основные значимые составляющие, т.е.выбрать только основные периоды сезонности (не больше 4-х периодов). Если вы выбрали 4 периода, то в модель включаются 4 пары sin и cos по одной паре на каждый период.
Пример. На основании данных «Сибнефть» был получен ряд котировок.
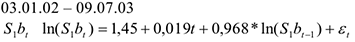
Но проводя анализ остатков было выяснено, что они не близки к нормальным, а их графический (визуальный) анализ позволил получить наличие сезонности. Дальнейший анализ выявил следующую сезонность. Оценки коэффициентов получены в Excel путем построения многомерной регрессии на соответствующие пары 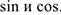 .
.
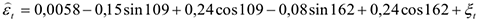
из всех периодов сезонности были выбраны 2 самых значимых (162 и 109)
Т.к. оценивание производится с помощью Excel — Пакет анализ —» Регрессия, то по таблице итогов было видно, что все коэффициенты значимы, 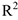 — высокий, а сами выбранные периоды имели экономический смысл:
— высокий, а сами выбранные периоды имели экономический смысл:
1-ый период:
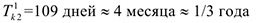
2-ой период:
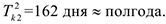
Замечание 1. Если после построения регрессии на sin и cos из пары синуса и косинуса значима только одна составляющая, то в модель все равно включают пару.
Замечание 2. Основная сложность этого метода состоит в определении значимых периодов. Существует множество различных критериев для определения значимых периодов. Один из самых простых критериев состоит в следующем: выписываются все логически значимые периоды, исходя из сущности…
Т.е.строится множество пар синусов и косинусов (порядка 10-15), а дальше, строя на них регрессию, исходя из значимости коэффициентов, максимизации и нормированных, устраняют лишние (незначимые) пары синусов и косинусов.
Использование сезонных фиктивных компонент при моделировании сезонных колебаний
При этом подходе строится регрессионная модель, в которую помимо факторов времени включают сезонные фиктивные переменные. Каждому из сезонов соответствует определенное сочетание фиктивных переменных, а 1 из сезонов за базовый.
Например. Если имеются поквартальные данные, то вводятся 3 новые фиктивные переменные. 1-ый квартал считается за базовый.

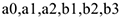 — коэффициенты, полученные MHK
— коэффициенты, полученные MHK
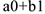 — коэффициент, характеризующий изменение 2-го квартала по сравнению с 1-м.
— коэффициент, характеризующий изменение 2-го квартала по сравнению с 1-м. 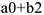 — коэффициент, характеризующий изменение 3-го квартала по сравнению с 1-м.
— коэффициент, характеризующий изменение 3-го квартала по сравнению с 1-м. 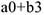 — коэффициент, характеризующий изменение 3-го квартала по сравнению с 1-м. Если коэффициент перед сезонной фиктивной переменной больше 0, то по сравнению с 1-ым кварталом был прирост.
— коэффициент, характеризующий изменение 3-го квартала по сравнению с 1-м. Если коэффициент перед сезонной фиктивной переменной больше 0, то по сравнению с 1-ым кварталом был прирост.
Если же 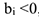 , то был спад по сравнению с 1-ым кварталом.
, то был спад по сравнению с 1-ым кварталом. 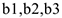 могут иметь разные знаки.
могут иметь разные знаки.
Этот метод удобен для выявления явных простых ссзонностей (квартальная, годовая зависимость), но с помощью него не удастся выявить сложную зависимость.
Анализ автокорреляции
Автокорреляция — это зависимость текущих значений ряда от предыдущих. Для учета автокорреляции строятся динамические экономические модели, т.е.матем.модели, которые в определенный момент времени учитывают значение входящих в них переменных, относящихся к настоящему и предыдущему моменту времени.
Например. Линейная авторегрессионная модель
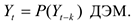
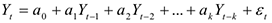
Используется в финансах, торговле.
Замечание.
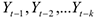
лагированные значения ряда.
Лаг — шаг во времени.
При построении ДЭМ часть лагированных значений может отсутствовать. При построении ДЭМ основной сложностью является нахождение оценок коэффициентов, т.к. МНК не применим. В этом случае для оценки коэффициентов используют метод максимума правдоподобия, обобщенный МНК и т.д.
Обобщением автокорреляционной модели служит Модель распределенных лагов.
При построении такой модели в правой части учитываются не только лагированные значения самого временного ряда, но и лагированные значения другого самостоятельного временного ряда.
Линейная модель в данном виде может выглядеть следующим образом:
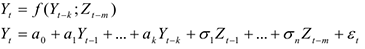
Например.
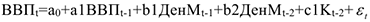
макроэкономическая модель валового внутреннего продукта. ДенМ — денежная масса
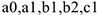 — вполне определенные числа, получаемые по выборке. Они характеризуют связь сегодняшнего значения ВВП с прошлым.
— вполне определенные числа, получаемые по выборке. Они характеризуют связь сегодняшнего значения ВВП с прошлым. 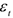 — остатки.
— остатки.
Модель считается хорошей, если остатки распределены нормально.
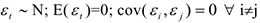
Замечание. В правой части в моделях распределения лагов, т.е.в качестве регрессоров не могут участвовать значения других временных рядов в тот же момент времени. Т.е.строить такую зависимость без выполнения определенных условий нельзя.
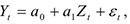
т.к. оценки коэффициентов будут плохие.
Такую модель можно рассматривать, если предварительно с помощью либо экономико-логических рассуждений, либо с помощью тестов на причинно-следственную связь было получено, что 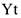 — это следствие изменения
— это следствие изменения 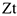 .
.
Например. Без всяких тестов можно строить модель следующего вида. Цена на золотые украшения в ювелирном магазине равна:
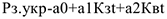
Тестом на причинно-следственную связь может являться тест Гренджера, который проверяет сразу следующую пару гипотез: l) служит причиной изменения 2) служит причиной изменения
Особого рассмотрения требует ситуация, когда обе гипотезы принимаются, т.е.совместное влияние 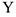 на
на 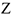 . В этом случае наблюдается перекрестная взаимосвязь при изучении временных рядов, состоящих из валютного курса $ и евро.
. В этом случае наблюдается перекрестная взаимосвязь при изучении временных рядов, состоящих из валютного курса $ и евро.
В этом случае строится векторная модель, которая в аналитическом виде представляет собой систему линейных уравнений, которая может выглядеть следующим образом.
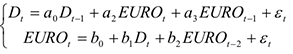
Замечание. Выбор наилучшего вида модели необходим для: 1)точного определения связи между явлениями 2)для более точного прогнозирования 3)для выявления настоящей истинной зависимости от прошлого.
Выбросы и структурные изменения
При анализе данных во временных рядах могут встречаться резко отличающиеся от общей тенденции значения.
Рассмотрим изменения курса доллара во времени.
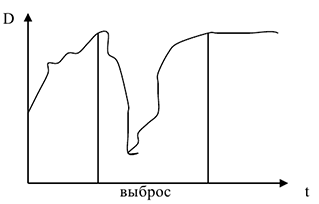
Выброс требует отдельного детального рассмотрения — выясняется, что этот период совпадает с событиями 11 сентября и ликвидацией последствий трагедии. Пример на структурные изменения: Курс рубля по отношению к евро.
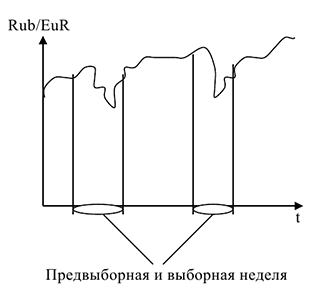
Предвыборная и выборная неделя
Такие временные периоды принято называть выбросами или структурными изменениями. Учитывать их можно следующим образом:
1) если после выброса ситуация вернулась на прежний уровень, то после проведения исследования отдельно описывается и обосновывается это несоответствие
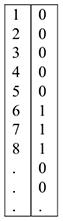
2) учет структурного изменения с помощью введения фиктивной переменной, которая считается следующим образом:
в период структурного изменения стоят единицы, а в остальных случаях — нули

Бизнес-циклы В ЭКОНОМИКЕ
При анализе макроэкономических показателей необходимо учитывать, что любая экономика развивается по циклам.
Экономический цикл — последовательная смена одних и тех же фаз.
Циклы отличаются друг от друга по амплитуде колебаний, по продолжительности, но последовательность фаз всегда остается неизменной.
Экономические бюро каждой страны определяют, текущую фазу цикла.
Существует два подхода к определению фаз:
1) фазы спада сменяются фазами подъема и наоборот
2) фаза спада — кризисная точка (яма) — подъем — пик — повторение цикла
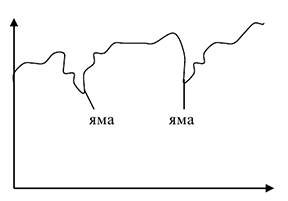
В этом случае толчком к развитию считается кризис, т.к. во время кризиса люди начинают активно экономить средства и вкладывать их в недвижимость. Объем инвестиций растет, объем наличной денежной массы уменьшается, начинает замедляться инфляция, следовательно, получаем фазу подъема.
В различных отраслях экономики существуют свои бизнсс-циклы. Например, в начале XX века американский ученый Н.Кузнецов выделил циклы в строительстве = 15 лет. Самые короткие циклы составляют 3-4 года.
Используются при формировании бюджета РФ. Балансируются следующим образом:
1) в течение года
2) в течение бизнес-цикла
При формировании общей экономической политики существуют вида подхода, связвнных с бизнес-циклами:
1) уменьшить амплитуду колебаний, т.е. не очень сильный подъем сменятся плавным спадом -выгодно обычным людям длинные затяжные периоды роста сменяются резким, коротким периодом спада — выгодно предпринимателям
Дискретные зависимые переменные
Ранее мы рассматривали переменные в моделях, которые являются независимыми и могут принимать дискретные значения. Например 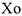 или
или 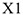 (фиктивные переменные), а вот зависимая переменная
(фиктивные переменные), а вот зависимая переменная 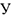 предполагалась количественной. В то же время довольно часто интересует нас величина , являющаяся дискретной. Выделим несколько типичных ситуаций.
предполагалась количественной. В то же время довольно часто интересует нас величина , являющаяся дискретной. Выделим несколько типичных ситуаций.
1.Выбор из нескольких альтернатив. Например: голосование на выборах (зависимая переменная -выбор из нескольких кандидатов); решение работать или не работать; выбор профессии, форма собственности предприятия и т.д.
Если есть только 2 возможности — бинарный выбор, то результат наблюдения, обычно описывающийся переменной, принимающей 2 значения 0 или 1. (Ехать не ехать, голосовать или
0 — нет
1 — да
В общем виде результат может быть записан как 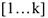
2.Ранжированный выбор — результат состоит из нескольких альтернатив. 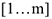 (Уровень образования — незаконченное среднее, среднее, среднетехническое, высшее; доход семьи — низкий, высокий, очень высокий).
(Уровень образования — незаконченное среднее, среднее, среднетехническое, высшее; доход семьи — низкий, высокий, очень высокий).
Соответствующая переменная ряда называется порядковой или ранжированной.
3.Количественная целочисленная характеристика. (Число предприятий, число выданных патентов, количество возвратов товара и т.д.)
Для таких моделей с дискретной зависимой переменной при построении модели формально возможно применение МНК для нахождения оценок коэффициентов. 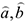
Остатки модели не будут близки к нормальному распределению, не будут случайными, поэтому сами оценки параметров 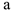 и
и 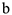 будут плохие, по ним получается никакой прогноз. Решение проблемы
будут плохие, по ним получается никакой прогноз. Решение проблемы
Строится модель бинарного и множественного выбора. Рассматриваются модели бинарного и множественного выбора на примере покупки автомобиля. 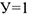 — купила
— купила 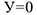 — не купила
— не купила
- в определенные периоды времени.
Например в периоды рекламы ясно, что решение о покупке автомобиля влияют самые разные факторы: доход, количество человек в семье, возраст членов семьи, место проживания, уровень образования членов семьи и т.д. Эти факторы можно представить с помощью вектора
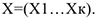
Выдвигая различные предположения о характере зависимости 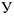 от
от 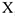 , мы будем получать разные модели. Далее мы рассмотрим 3 модели: 1)Линейная модель вероятности
, мы будем получать разные модели. Далее мы рассмотрим 3 модели: 1)Линейная модель вероятности
2)logit-modеl
3)probit-modеl
Начнем с линейной модели вероятности. Воспользуемся обычной регрессионной моделью, где 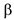 -вектор неизвестных коэффициентов, — вектор столбец. принимает значение 0 или 1, a
-вектор неизвестных коэффициентов, — вектор столбец. принимает значение 0 или 1, a 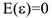 (для построения МНК)
(для построения МНК)
Тогда можно записать, что
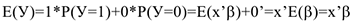
Мы получили, что вероятность того, что 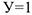 равно
равно 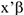 . Это и есть линейная модель вероятности. Основным недостатком этой модели является тот факт, что прогнозные значения вероятности
. Это и есть линейная модель вероятности. Основным недостатком этой модели является тот факт, что прогнозные значения вероятности 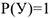 могут лежать вне отрезка [0,1], что, конечно же не подлежит разумной интерпритации. Справиться с недостатком этой модели можно, если предположить, что вероятность равна некоторой функции
могут лежать вне отрезка [0,1], что, конечно же не подлежит разумной интерпритации. Справиться с недостатком этой модели можно, если предположить, что вероятность равна некоторой функции 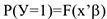 , где
, где 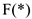 — некоторая функция, принадлежащая [0;1]. Наиболее часто в качестве функции
— некоторая функция, принадлежащая [0;1]. Наиболее часто в качестве функции 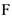 используют либо функцию нормального распределения (probit) либо функцию логического распределения (logit). Результатом применения и построения logit-probit модели, является прогноз вероятности того, что У примет значение 1. Например: с помощью logit-probit модели можно построить модель вероятности банкротства предприятия. Зависимая переменная — вероятность банкротства, независимые факторы — факторы финансового состояния предприятия. 1 — предприятие в течение 3-х месяцев стало банкротом 0 — не стало. В данной модели оценки коэффициентов находятся с помощью, например, метода максимума правдоподобия, а основная проблема — определить пороговое значение вероятности, после которой надо волноваться.
используют либо функцию нормального распределения (probit) либо функцию логического распределения (logit). Результатом применения и построения logit-probit модели, является прогноз вероятности того, что У примет значение 1. Например: с помощью logit-probit модели можно построить модель вероятности банкротства предприятия. Зависимая переменная — вероятность банкротства, независимые факторы — факторы финансового состояния предприятия. 1 — предприятие в течение 3-х месяцев стало банкротом 0 — не стало. В данной модели оценки коэффициентов находятся с помощью, например, метода максимума правдоподобия, а основная проблема — определить пороговое значение вероятности, после которой надо волноваться.
Возможно эти страницы вам будут полезны:
- Примеры решения задач по эконометрике
- Курсовая работа по эконометрике
- Заказать работу по эконометрике
- Лабораторная работа по эконометрике
- Решение задач по эконометрике в Excel
- Системы эконометрических уравнений