Оглавление:
Экономисты используют количественные данные для наблюдения за ходом развития экономики, ее анализа и прогнозов. Набор статистических методов, используемых для этих целей, называется в совокупности эконометрикой.
| Если что-то непонятно — вы всегда можете написать мне в WhatsApp и я вам помогу! |
Эконометрика
Эконометрика – это наука, связанная с эмпирическим выводом экономических законов, т.е. используются данные для того, чтобы получить количественные зависимости для экономических соотношений.
Пример выполненной лабораторной работы №1. Тема: «Парная регрессия и корреляция»
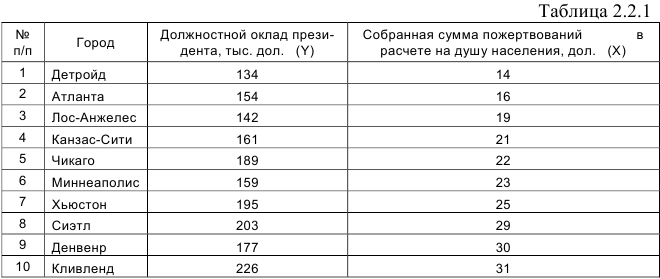
Задание: Периодически в средствах массовой информации обсуждаются высокие должностные оклады президентов благотворительных организаций. Дана информация о десяти крупнейших филиалах общества United Way в таблице 2.2.1.
Требуется:
- Построить поле корреляции и сформулировать гипотезу о форме связи.
- Рассчитать параметры уравнений линейной, степенной, экспоненциальной, полулогарифмической, обратной, гиперболической парной регрессий.
- Оценить тесноту связи с помощью показателей корреляции и детерминации.
- Дать с помощью среднего (общего) коэффициента эластичности сравнительную оценку силы связи фактора с результатом.
- Оценить с помощью средней ошибки аппроксимации качество уравнений.
- Оценить с помощью
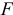 -критерия Фишера статистическую надежность результатов регрессионного моделирования.
-критерия Фишера статистическую надежность результатов регрессионного моделирования. - По значениям характеристик, рассчитанных в пп. 3, 5 и 6, выберать лучшее уравнение регрессии и дайть его обоснование.
- Рассчитайть прогнозное значение результата, если прогнозное значение фактора увеличится на 6 % от его среднего уровня. Определить доверительный интервал прогноза для уровня значимости
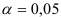 .
. - Оценить надежность и точность полученного прогноза.
Решение:
- Для условия задачи поле корреляции выглядит следующим образом (Рисунок 2.2.1):
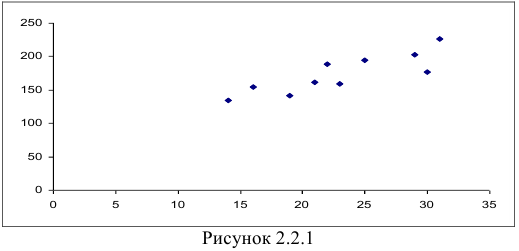
По расположению точек можно предположить, что между должностным окладом президента 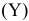 и собранной суммой пожертвований
и собранной суммой пожертвований 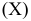 существует прямая линейная зависимость.
существует прямая линейная зависимость.
- Определим параметры уравнения парной линейной регрессии
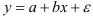 . Вычисления организуем в таблицу 2.2.2:
. Вычисления организуем в таблицу 2.2.2:
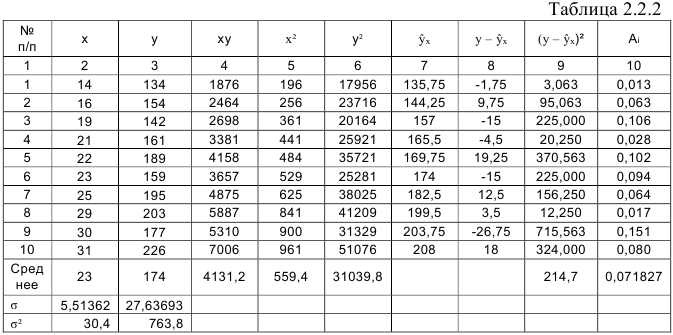
Напомним, что средние значения рассчитываются по формулам
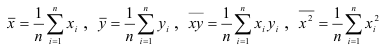
и т.д., где 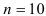 (число наблюдений в рассматриваемой задаче). Дисперсия определяется по формулам
(число наблюдений в рассматриваемой задаче). Дисперсия определяется по формулам 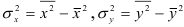 , а среднеквадратическое отклонение
, а среднеквадратическое отклонение 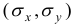 есть корень квадратный из дисперсии.
есть корень квадратный из дисперсии.
По формулам находим:
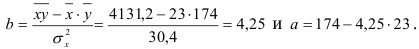
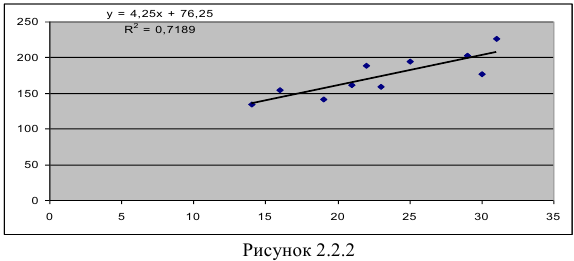
Т.о. уравнение регрессии запишется в виде:
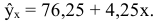
Интерпретация коэффициента регрессии. С увеличением суммы пожертвований на душу населения на один доллар должностной оклад президента благотворительной организации увеличивается на 4,25 тыс. дол.
1) Рассчитаем линейный коэффициент корреляции по формуле:
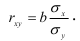
С учетом вычислений в столбцах 2,3 и 4 таблицы получим
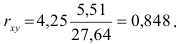
Т.е. связь между изучаемыми переменными прямая (так как 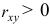 ), тесная (так как
), тесная (так как 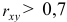 ). Определим коэффициент детерминации
). Определим коэффициент детерминации 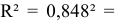
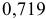 .Т.е. 71,9% вариации должностного оклада объясняется вариацией пожертвований.
.Т.е. 71,9% вариации должностного оклада объясняется вариацией пожертвований.
2) Рассчитаем средний коэффициент эластичности:
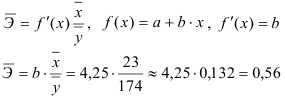
Это означает, что при изменении фактора (собранной суммы пожертвований на душу населения) на 1% от своего среднего значения, результат (должностной оклад президента) изменится в среднем по совокупности на 0,56% от своего среднего значения.
3) Найдем среднюю ошибку аппроксимации:
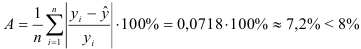
Это означает, что качество рассматриваемой модели хорошее. 4) Определим статистическую надежность результатов регрессионного моделирования, для этого находим
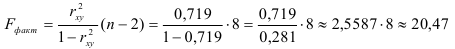
По таблице значений -критерия Фишера для уровня значимости находим:

Так как
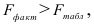
то гипотеза о статистической незначимости уравнения регрессии отвергается и принимается гипотеза о статистической значимости и надежности уравнения регрессии в целом.
Обработка данных в табличном редакторе Excel приводит к следующему результату (Рисунок 2.2.2):
- Определим параметры уравнения полулогарифмической регрессии
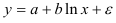 . Предварительно проведем процедуру линеаризации переменных. Для этого сделаем замену
. Предварительно проведем процедуру линеаризации переменных. Для этого сделаем замену 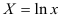 и определим параметры уравнения
и определим параметры уравнения 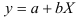 . Вычисления организуем в таблицу 2.2.3:
. Вычисления организуем в таблицу 2.2.3:
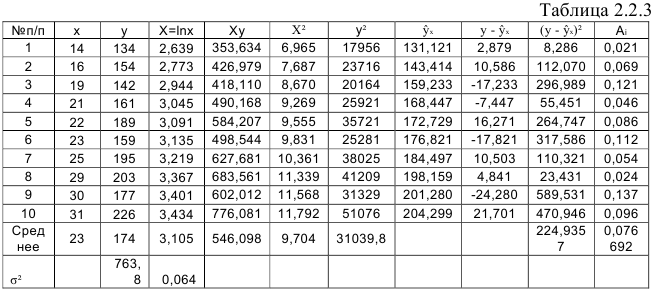
По формулам находим:
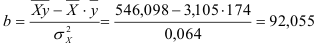
и
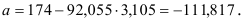
Т.о. уравнение регрессии запишется в виде:
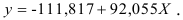
После замены получим
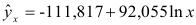
1) Рассчитаем индекс корреляции по формуле:
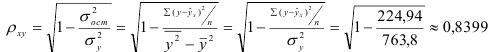
Определим коэффициент детерминации
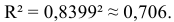
Т.е. 70,6% вариации должностного оклада объясняется вариацией пожертвований.
2) Рассчитаем средний коэффициент эластичности:
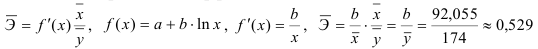
Это означает, что при изменении фактора (собранной суммы пожертвований на душу населения) на 1% от своего среднего значения, результат (должностной оклад президента) изменится в среднем по совокупности на 0,53% от своего среднего значения.
3) Найдем среднюю ошибку аппроксимации:
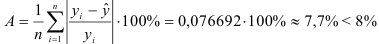
Это означает, что качество рассматриваемой модели хорошее.
4) Определим статистическую надежность результатов регрессионного моделирования, для этого находим
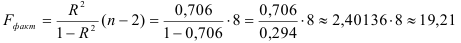
По таблице значений -критерия Фишера для уровня значимости находим:
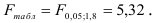
Так как
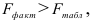
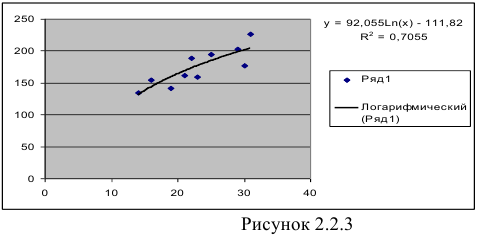
то гипотеза о статистической незначимости уравнения регрессии отвергается и принимается гипотеза о статистической значимости и надежности уравнения регрессии в целом. В Excel получим следующий результат (Рисунок 2.2.3):
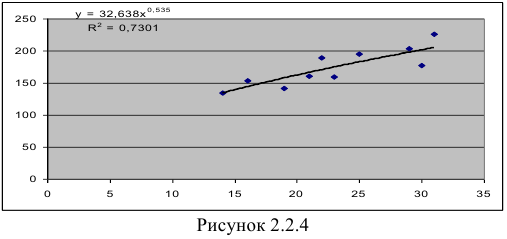
- Построению степенной модели
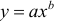 предшествует процедура линеаризации переменных. Проведем линеаризацию путем логарифмирования обеих частей уравнения:
предшествует процедура линеаризации переменных. Проведем линеаризацию путем логарифмирования обеих частей уравнения: 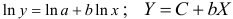 , где
, где 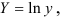
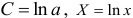 .
.
Для расчетов используем данные таблицы 2.2.4:
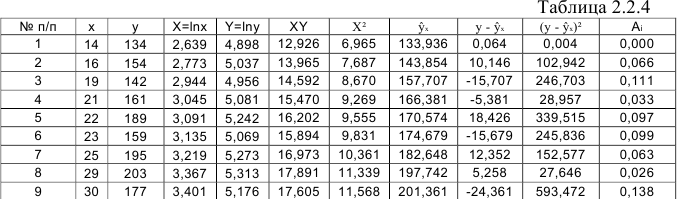

По формулам находим:
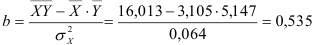
и
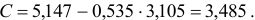
Т.о. уравнение регрессии запишется в виде:
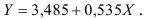
После замены получим:
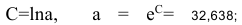
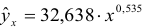
1) Рассчитаем индекс корреляции по формуле:
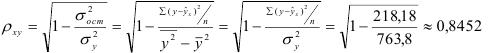
Определим коэффициент детерминации
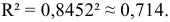
Т. е. 71,4 % вариации должностного оклада объясняется вариацией пожертвований.
2) Рассчитаем средний коэффициент эластичности:
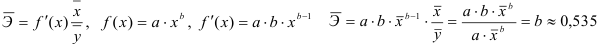
Это означает, что при изменении фактора (собранной суммы пожертвований на душу населения) на 1% от своего среднего значения, результат (должностной оклад президента) изменится в среднем по совокупности на 0,54% от своего среднего значения.
3) Найдем среднюю ошибку аппроксимации:
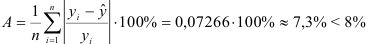
Это означает, что качество рассматриваемой модели хорошее.
4) Определим статистическую надежность результатов регрессионного моделирования, для этого находим
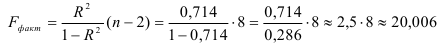
По таблице значений 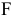 -критерия Фишера для уровня значимости
-критерия Фишера для уровня значимости 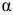 = 0,05 находим:
= 0,05 находим:
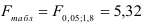
Так как
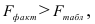
то гипотеза о статистической незначимости уравнения регрессии отвергается и принимается гипотеза о статистической значимости и надежности уравнения регрессии в целом.
В Excel получим следующий результат (Рисунок 2.2.4):
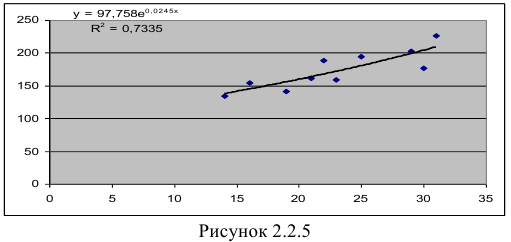
- Построению экспоненциальной модели
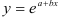 предшествует процедура линеаризации переменных. Проведем линеаризацию путем логарифмирования обеих частей уравнения:
предшествует процедура линеаризации переменных. Проведем линеаризацию путем логарифмирования обеих частей уравнения: 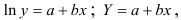 , где
, где 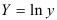 . Для расчетов используем данные таблицы 2.2.5:
. Для расчетов используем данные таблицы 2.2.5:
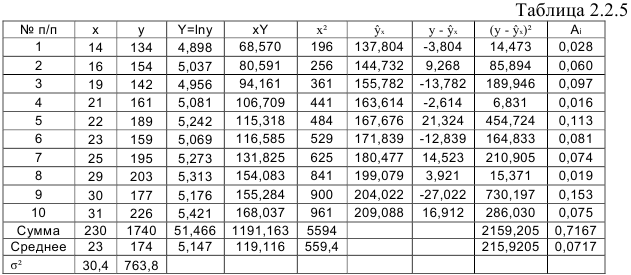
По формулам находим:
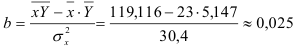
и
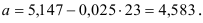
Т.о. уравнение регрессии запишется в виде:
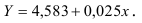
После замены получим:
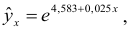
или
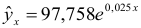
1) Рассчитаем индекс корреляции по формуле:
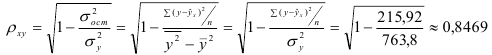
Определим коэффициент детерминации
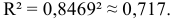
Т.е. 71,7% вариации должностного оклада объясняется вариацией пожертвований.
2) Рассчитаем средний коэффициент эластичности:
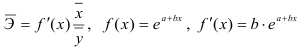
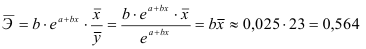
Это означает, что при изменении фактора (собранной суммы пожертвований на душу населения) на 1% от своего среднего значения, результат (должностной оклад президента) изменится в среднем по совокупности на 0,56% от своего среднего значения.
3) Найдем среднюю ошибку аппроксимации:
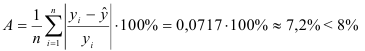
Это означает, что качество рассматриваемой модели хорошее. 4) Определим статистическую надежность результатов регрессионного моделирования, для этого находим
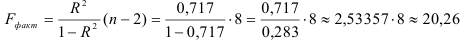
По таблице значений -критерия Фишера для уровня значимости = 0,05 находим:
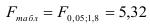
Так как
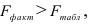
то гипотеза о статистической незначимости уравнения регрессии отвергается и принимается гипотеза о статистической значимости и надежности уравнения регрессии в целом.
В Excel получим следующий результат (Рисунок 2.2.5):
- Определим параметры уравнения обратной регрессии
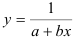 .
.
Предварительно проведем процедуру линеаризации переменных. Для этого сделаем замену 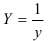 и определим параметры уравнения
и определим параметры уравнения 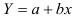 . Вычисления организуем в таблицу 2.2.6:
. Вычисления организуем в таблицу 2.2.6:

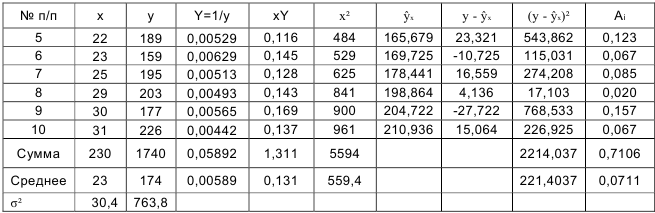
По формулам находим:
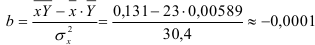
и
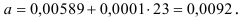
Т.о. уравнение регрессии запишется в виде:
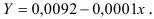
После замены получим:
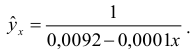
1) Рассчитаем индекс корреляции по формуле:
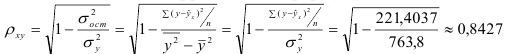
Определим коэффициент детерминации
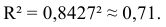
Т.е. 71% вариации должностного оклада объясняется вариацией пожертвований.
2) Рассчитаем средний коэффициент эластичности:
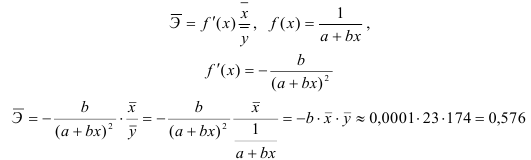
Это означает, что при изменении фактора (собранной суммы пожертвований на душу населения) на 1% от своего среднего значения, результат (должностной оклад президента) изменится в среднем по совокупности на 0,56% от своего среднего значения.
3) Найдем среднюю ошибку аппроксимации:
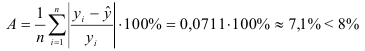
Это означает, что качество рассматриваемой модели хорошее. 4) Определим статистическую надежность результатов регрессионного моделирования, для этого находим
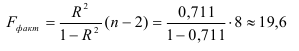
По таблице значений -критерия Фишера для уровня значимости = 0,05 находим:
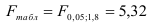
Так как
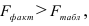
то гипотеза о статистической незначимости уравнения регрессии отвергается и принимается гипотеза о статистической значимости и надежности уравнения регрессии в целом.
- Определим параметры уравнения равносторонней гиперболы
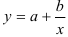 Предварительно проведем процедуру линеаризации переменных. Для этого сделаем замену
Предварительно проведем процедуру линеаризации переменных. Для этого сделаем замену 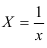 и определим параметры уравнения
и определим параметры уравнения 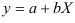 .
.
Вычисления организуем в таблицу 2.2.7:
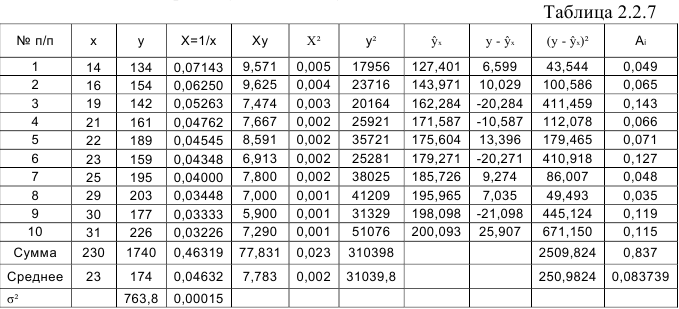
По формулам находим:
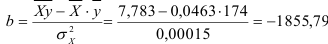
и
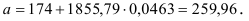
Т. о. уравнение регрессии запишется в виде:
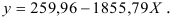
После замены получим
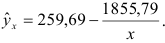
2) Рассчитаем индекс корреляции по формуле:
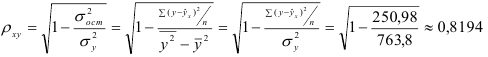
Определим коэффициент детерминации
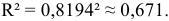
Т.е. 67,1% вариации должностного оклада объясняется вариацией пожертвований.
2) Рассчитаем средний коэффициент эластичности:
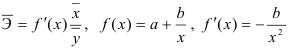
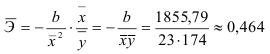
Это означает, что при изменении фактора (собранной суммы пожертвований на душу населения) на 1% от своего среднего значения, результат (должностной оклад президента) изменится в среднем по совокупности на 0,53% от своего среднего значения.
3) Найдем среднюю ошибку аппроксимации:
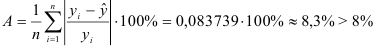
Это означает, что качество рассматриваемой модели удовлетворительное.
4) Определим статистическую надежность результатов регрессионного моделирования, для этого находим
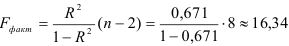
По таблице значений -критерия Фишера для уровня значимости = 0,05 находим:
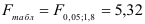
Так как
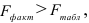
то гипотеза о статистической незначимости уравнения регрессии отвергается и принимается гипотеза о статистической значимости и надежности уравнения регрессии в целом. 8) Для анализа составим таблицу 2.2.8:
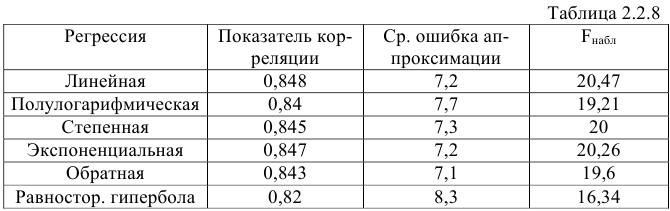
Из таблицы видим, что рассматриваемую в задаче зависимость лучше всего описывает уравнение линейной регрессии, поскольку для этой модели показатель корреляции оказался больше, при этом качество линейной модели хорошее и уравнение линейной регрессии статистически надёжно.
Рассчитаем прогнозное значение 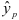 . Для этого найдем
. Для этого найдем
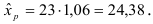
Построим точечный прогноз:
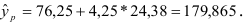
Построим 95% доверительный интервал для прогноза. Определим среднюю стандартную ошибку прогноза 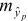 :
:
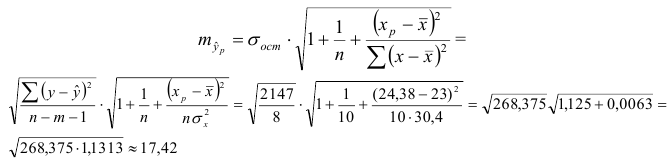
Далее строим доверительный интервал прогноза:
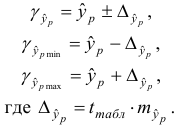
По таблице находим для уровня значимости по условию 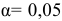 и числа степеней свободы
и числа степеней свободы
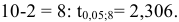
И, следовательно,
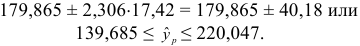
Таким образом, с вероятностью 0,95 можно утверждать, что прогнозное значение оклада президента отдельной благотворительной организации, которая соберет пожертвований в расчете на душу населения на 6% больше от среднего значения, будет находиться в интервале от 139,685 до 220,047тыс. долларов. Прогноз оказался надежным.
Оценим точность полученного прогноза
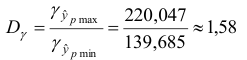
Прогноз оказался не очень точным.
Пример выполненной лабораторной работы № 2 Тема : «Множественная регрессия»
Задание: Имеются данные по странам

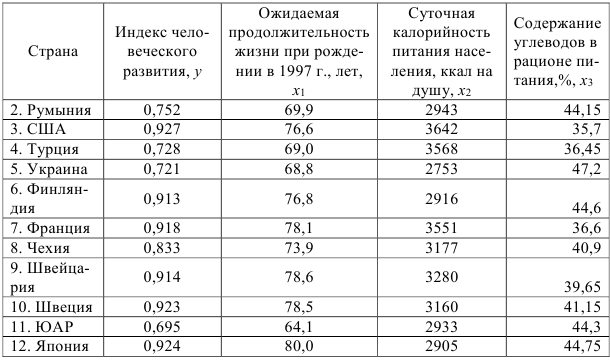
Требуется:
- Найти матрицу парных коэффициентов корреляции. Сделать выводы.
- Построить уравнение множественной регрессии в стандартизованной и естественной форме.
- Сделать выводы о силе влияния факторов на результат на основе
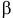 -коэффициентов и средних коэффициентов эластичности.
-коэффициентов и средних коэффициентов эластичности. - Рассчитать линейные коэффициенты частной корреляции и коэффициент множественной корреляции. Проанализировать линейные коэффициенты парной и частной корреляции. Рассчитать значение скорректированного коэффициента множественной детерминации.
- С помощью общего
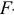 -критерия Фишера оценить статистическую надежность уравнения регрессии.
-критерия Фишера оценить статистическую надежность уравнения регрессии. - С помощью частных -критериев Фишера оценить, насколько целесообразно включение в уравнение регрессии фактора
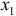 , после фактора
, после фактора 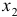 и насколько целесообразно включение в уравнение регрессии фактора после фактора .
и насколько целесообразно включение в уравнение регрессии фактора после фактора . - Оценить с помощью
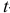 -критерия Стьюдента статистическую значимость коэффициентов при переменных и множественного уравнения регрессии.
-критерия Стьюдента статистическую значимость коэффициентов при переменных и множественного уравнения регрессии. - Сделать выводы.
Решение:
- Матрицу парных коэффициентов можно получить, рассчитав линейные коэффициенты парной корреляции аналогично тому, как это делалось в первой лабораторной работе. Однако, эффетивнее воспользоваться инструментом «Корреляция» ППП Exel. При построении матрицы парных коэффициентов корреляции исследуемых показателей, учитываем, что эта матрица должна быть симметричной относительно главной диагонали:
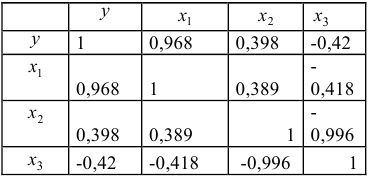
Очевидно, что факторы 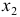 и
и 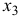 явно коллинеарны
явно коллинеарны 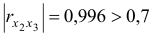 , то есть они дублируют друг друга, один из них следует исключить. Для дальнейшего анализа предпочтительнее оставить фактор , так как он меньше коррелирует с фактором
, то есть они дублируют друг друга, один из них следует исключить. Для дальнейшего анализа предпочтительнее оставить фактор , так как он меньше коррелирует с фактором 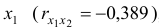 , чем фактор
, чем фактор 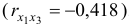 .
.
- Линейное уравнение регрессии
 от и имеет вид:
от и имеет вид:
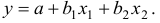
Для расчета его параметров применим метод стандартизации переменных и построим искомое уравнение в стандартизованном масштабе:
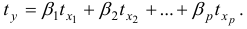
В нашем примере число объясняющих факторов 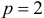 . Стандартизованные коэффициенты регрессии (-коэффициенты) определяются из следующей системы уравнений:
. Стандартизованные коэффициенты регрессии (-коэффициенты) определяются из следующей системы уравнений:
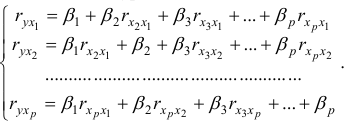
При эта система принимает вид:
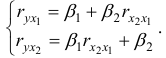
Для нахождения -коэффициентов применим метод Крамера:
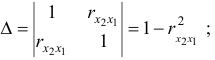

Получим уравнение в стандартизированном масштабе
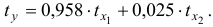
Для построения уравнения в естественной форме рассчитаем  и
и  используя формулы для перехода от
используя формулы для перехода от 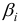 к
к 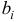 :
:
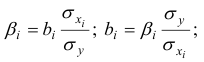
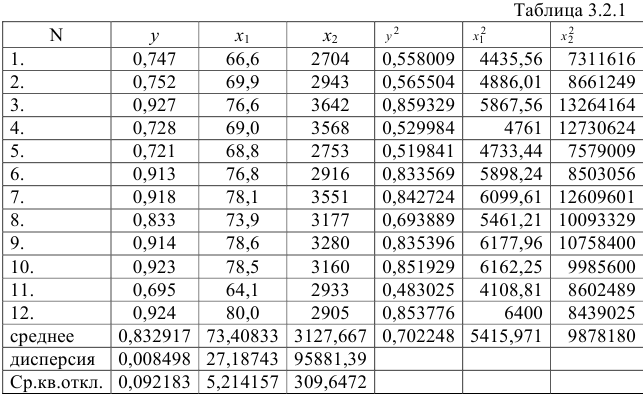
Для расчета необходимых величин составим расчетную таблицу 3.2.1.
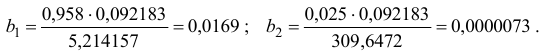
Значение параметра 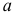 определим из соотношения
определим из соотношения
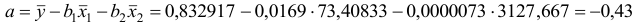
Получим уравнение в естественной форме
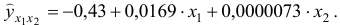
- При сравнении модулей значений стандартизованных коэффициентов
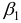 и
и 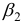 приходим к выводу, что сила влияния
приходим к выводу, что сила влияния 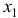 на
на 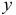 оказалась большей, чем сила влияния
оказалась большей, чем сила влияния 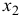 :
:
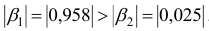
К аналогичным выводам можно прийти, рассчитав средние коэффициенты эластичности:
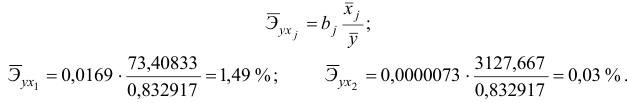
С увеличением на 1 % от его среднего уровня возрастает на 1,49 % от своего среднего уровня; при повышении на 1 % от его среднего уровня повышается на 0,03 % от своего среднего уровня. Очевидно, что сила влияния на оказалась большей, чем сила .
- Линейные коэффициенты частной корреляции рассчитываются по рекуррентной формуле:
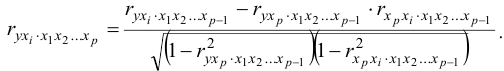
При получаем:
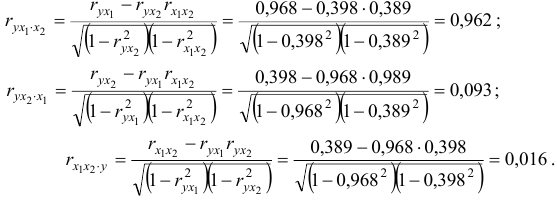
Коэффициенты частной корреляции дают более точную характеристику тесноты связи двух признаков, чем коэффициенты парной корреляции, так как очищают парную зависимость от взаимодействия данной пары признаков с другими признаками, представленным в модели. Сравним парные и частные коэффициенты корреляции:
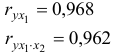
выводы о связи между 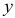 и совпадают;
и совпадают;
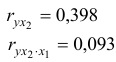
связь между и на основе частного коэффициента корреляции оказалась гораздо слабее;
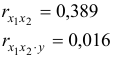
связь между и на основе частного коэффициента корреляции оказалась гораздо слабее.
Различия в выводах на основе частных и парных коэффициентов корреляции различаются из-за довольно существенной межфакторной связи
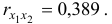
Расчет линейного коэффициента множественной корреляции выполним с использованием коэффициентов 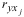 и
и 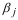 :
:
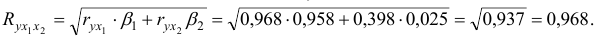
Зависимость от и характеризуется как тесная, в которой 93,7 % вариации среднего душевого дохода определяются вариацией учтенных в модели факторов.
Прочие факторы, не включенные в модель, составляют соответственно 6,3 % от общей вариации
Скорректированный индекс множественной детерминации содержит поправку на число степеней свободы и рассчитывается следующим образом:
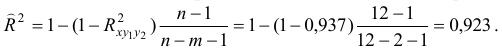
- Общий
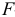 -критерий проверяет гипотезу
-критерий проверяет гипотезу 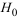 о статистической незначимости уравнения регрессии и показателя тесноты связи:
о статистической незначимости уравнения регрессии и показателя тесноты связи:
Определяем по таблице значений -критерия Фишера
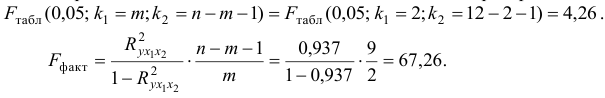
Так как 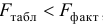 , то гипотеза о случайной природе оцениваемых характеристик отклоняется, и с вероятностью
, то гипотеза о случайной природе оцениваемых характеристик отклоняется, и с вероятностью 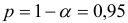 делаем заключение о статистической значимости уравнения в целом и показателя тесноты связи, которые сформировались под неслучайным воздействием факторов и .
делаем заключение о статистической значимости уравнения в целом и показателя тесноты связи, которые сформировались под неслучайным воздействием факторов и .
- Частные -критерии —
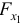 и
и 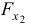 оценивают статистическую значимость присутствия факторов и в уравнении множественной регрессии. оценивает, насколько целесообразно включение в уравнение регрессии фактора после фактора , a указывает целесообразность включения в уравнение регрессии фактора после фактора .
оценивают статистическую значимость присутствия факторов и в уравнении множественной регрессии. оценивает, насколько целесообразно включение в уравнение регрессии фактора после фактора , a указывает целесообразность включения в уравнение регрессии фактора после фактора .
Фактическое значение частного -критерия рассчитывается по формуле:
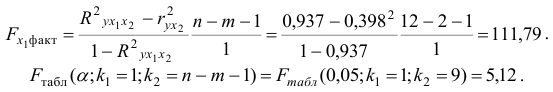
Так как
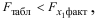
то гипотезу о несущественности прироста 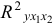 за счет включения дополнительного фактора отклоняем и приходим к выводу о статистически подтвержденной целесообразности включения в уравнение регрессии фактора после фактора .
за счет включения дополнительного фактора отклоняем и приходим к выводу о статистически подтвержденной целесообразности включения в уравнение регрессии фактора после фактора .
Целесообразность включения в модель фактора после фактора проверяет 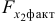 :
:
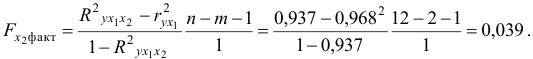
Так как
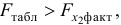
то гипотезу о несущественности прироста 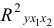 за счет включения дополнительного фактора принимаем. Это означает нецелесообразность включения в уравнение регрессии фактора после фактора .
за счет включения дополнительного фактора принимаем. Это означает нецелесообразность включения в уравнение регрессии фактора после фактора .
- Оценка с помощью
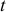 -критерия Стьюдента значимости коэффициентов
-критерия Стьюдента значимости коэффициентов 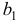 и
и 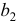 связана с сопоставлением их значений с величиной их случайных ошибок
связана с сопоставлением их значений с величиной их случайных ошибок 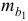 и
и 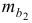 . Расчет значений случайных ошибок достаточно сложен и трудоёмок. Поэтому предлагается расчёт значения -критерия Стьюдента по следующим формулам:
. Расчет значений случайных ошибок достаточно сложен и трудоёмок. Поэтому предлагается расчёт значения -критерия Стьюдента по следующим формулам:
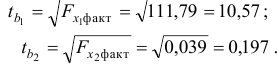
Табличные (критические) значения -критерия Стьюдента зависят от принятого уровня значимости 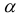 и от числа степеней свободы
и от числа степеней свободы
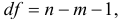
где 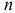 — число единиц совокупности,
— число единиц совокупности, 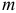 — число факторов в уравнении.
— число факторов в уравнении.
В нашем примере
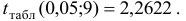
Так как 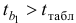 , то коэффициент регрессии является статистически значимым, надежным, на него можно опираться в анализе и в прогнозе. Так как
, то коэффициент регрессии является статистически значимым, надежным, на него можно опираться в анализе и в прогнозе. Так как 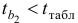 то приходим к заключению, что величина является статистически незначимой, ненадежной в силу того, что формируется преимущественно под воздействием случайных факторов. Еще раз подтверждается статистическая значимость влияния
то приходим к заключению, что величина является статистически незначимой, ненадежной в силу того, что формируется преимущественно под воздействием случайных факторов. Еще раз подтверждается статистическая значимость влияния 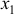 на
на 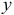 и ненадежность, незначимость влияния
и ненадежность, незначимость влияния 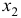 на . 8.Проведенные выше исследования показывают, что в данном примере парная регрессионная модель зависимости индекса человеческого развития от средней ожидаемой продолжительности жизни является достаточно статистически значимой, и нет необходимости улучшать ее, включая дополнительный фактор (суточную калорийность питания).
на . 8.Проведенные выше исследования показывают, что в данном примере парная регрессионная модель зависимости индекса человеческого развития от средней ожидаемой продолжительности жизни является достаточно статистически значимой, и нет необходимости улучшать ее, включая дополнительный фактор (суточную калорийность питания).
Пример выполненной лабораторной работы № 3 Тема : « Аддитивная и мультипликативная модели временных рядов »
Задание: Имеются поквартальные данные об объемах потребления электроэнергии жителям региона за 4 года (Таблица 5.2.1).
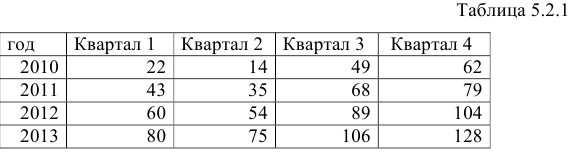
Требуется:
1) Построить аддитивную модель;
2) Построить мультипликативную модель;
3) Выполнить прогноз потребления электроэнергии на первый квартал 2014 года.
Решение:
1) Аддитивная модель
Шаг 1. Проведем выравнивание исходных уровней ряда методом скользящей средней, для этого:
- Просуммируем уровни ряда последовательно за каждые четыре квартала со сдвигом на один момент времени.
- Разделив полученные суммы на четыре, найдем скользящую среднюю. Полученные таким образом значения не содержат сезонной компоненты.
- Приведем эти значения в соответствии с фактическими моментами времени, для чего найдем средние значения из двух последовательных скользящих средних — центрированные скользящие средние.
Шаг 2. Найдем оценки сезонной компоненты как разность между фактическими уровнями ряда и центрированными скользящими средними. Результат занесем в таблицу (Таблица 5.2.2).
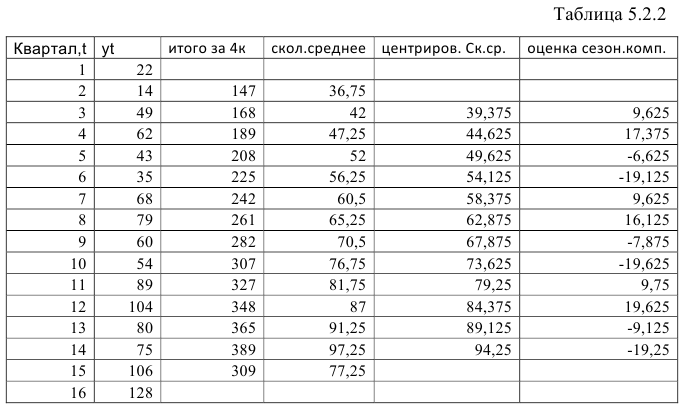
Используем полученные оценки для расчета значений сезонной компоненты 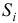 . Для этого найдем средние значения за каждый квартал по всем годам.
. Для этого найдем средние значения за каждый квартал по всем годам.
В моделях с сезонной компонентой обычно предполагается, что сезонные взаимодействия за период взаимопогашаются. В аддитивной модели это выражается в том, что сумма значений сезонной компоненты по всем кварталам должна быть равна нулю. Этот факт мы будем использовать для корректировки сезонной компоненты (Таблица 5.2.3).
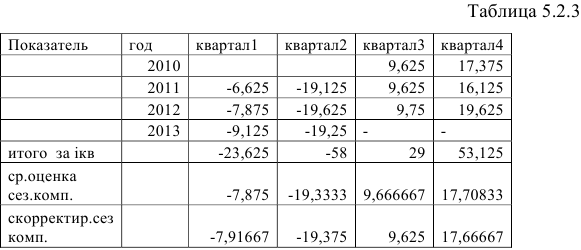
Сумма значений сезонной компоненты по всем кварталам составит:
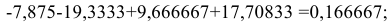
Определим корректирующий коэффициент:
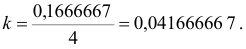
Рассчитаем скорректированные значения сезонной компоненты как разность между ее средней оценкой и корректирующим коэффициентом:
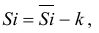
где 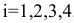 . Проверим условие равенства нулевой суммой значений сезонной компоненты:
. Проверим условие равенства нулевой суммой значений сезонной компоненты:
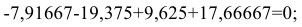
Шаг 3. Устраним сезонную компоненту, вычитая ее значение из каждого уровня исходного временного ряда. Эти значения рассчитываются для каждого момента времени и содержат только тенденцию и случайную компоненту (Таблица 5.2.4).

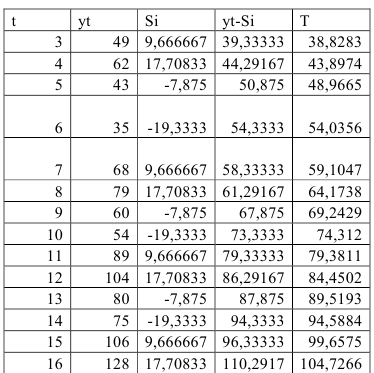
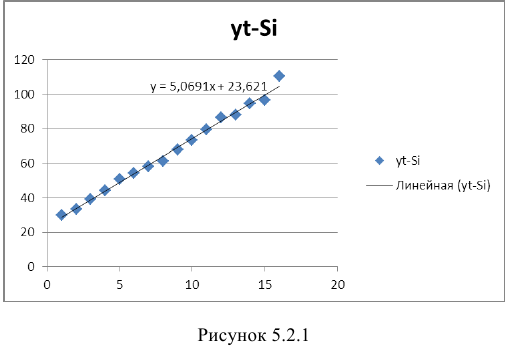
Шаг 4. Определим компоненту  для данной модели путем построения линейного тренда по данным, находящимся в столбце
для данной модели путем построения линейного тренда по данным, находящимся в столбце  . Получим тренд (Рисунок 5.2.1.):
. Получим тренд (Рисунок 5.2.1.):
2) Мультипликативная модель.
Шаг 1. Выравнивание исходных уровней ряда методом скользящей средней были выполнены при построении аддитивной модели.
Шаг 2. Найдем оценки сезонной компоненты как отношение фактических уровней ряда к центрированным скользящим средним. Результат занесем в таблицу (Таблица 5.2.5).
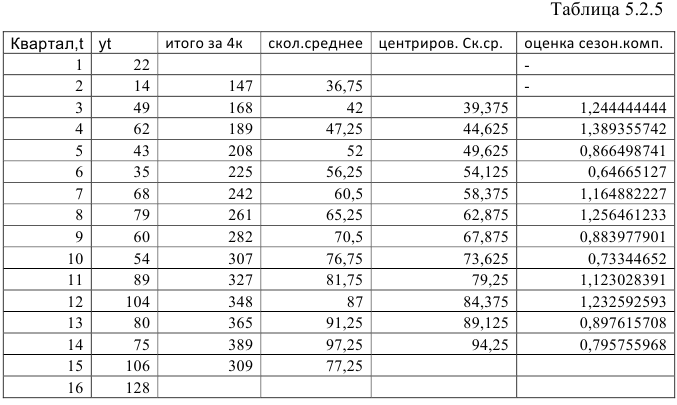
Полученные значения занесем в таблицу 5.2.6:
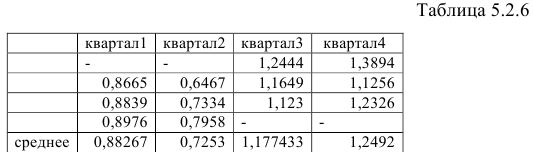
Определим корректирующий множитель. Он равен отношению 4 к сумме вычисленных индексов:
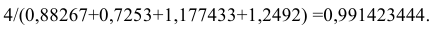
На корректирующий множитель умножается значение каждого из четырех квартальных индексов. Сумма скорректированных индексов должна быть равна числу периодов сезонности (в данном примере числу кварталов). В данном примере скорректированные индексы следующие:
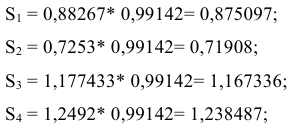
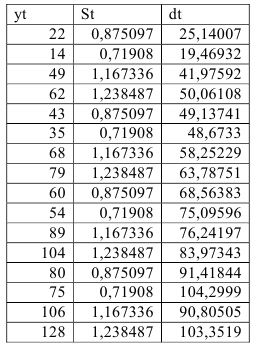
Шаг 3. Десезонализированные данные вычисляются как отношение фактических уровней временного ряда к соответствующему индексу сезонности:
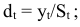
Вычислим десезонализированные данные (Таблица 5.2.7):
Шаг 4. По десезонализированным данным строится тренд, как уравнение парной регрессии, где 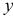 -зависимая переменная, а
-зависимая переменная, а 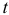 — объясняющий фактор. Линейный тренд в данном примере имеет вид:
— объясняющий фактор. Линейный тренд в данном примере имеет вид:
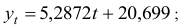
Выполним прогноз на первый квартал 2014 года по аддитивной модели:
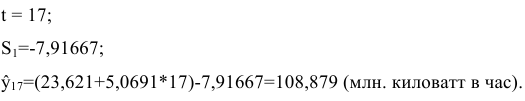
Выполним прогноз на первый квартал 2014 года по мультипликативной модели:
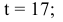
Коэффициент сезонности:
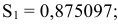
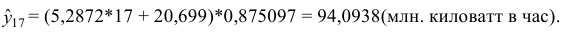
Пример выполненной лабораторной работы №4 Тема: «Автокорреляция уровней временного ряда и выявление его структуры»
Задание:
Имеются данные за 30 последовательных периодов:

Требуется: рассчитать коэффициенты автокорреляции до максимально возможного уровня; построить автокорреляционную функцию; сделать выводы о структуре ряда; предложить модель авторегрессии для описания ряда.
Решение:
Для расчета коэффициента автокорреляции уровней ряда 1-го порядка 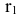 составим таблицу 6.2.1.
составим таблицу 6.2.1.
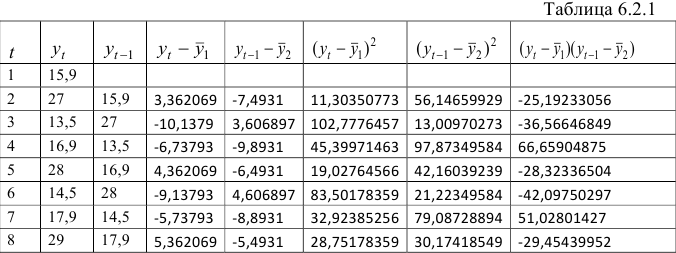
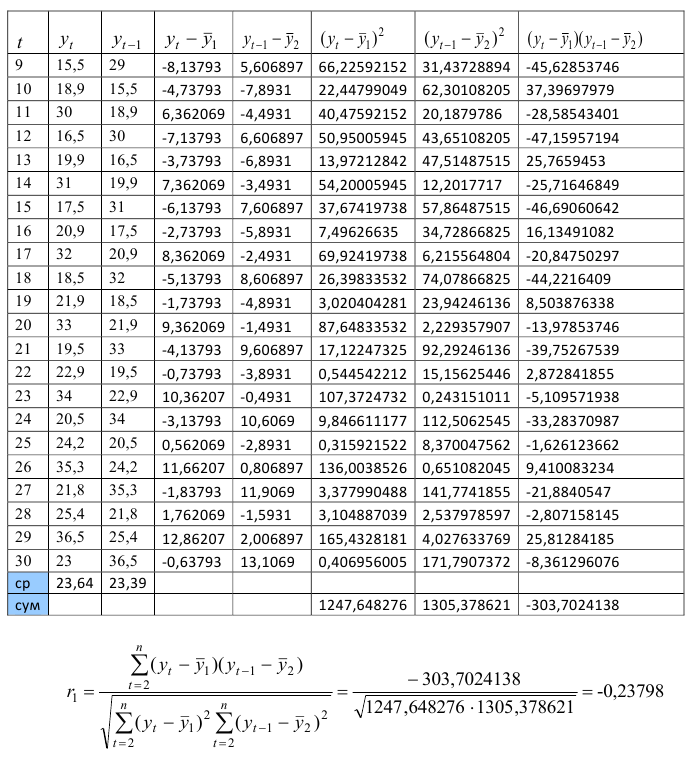
Полученное значение свидетельствует о слабой зависимости между уровнями временного ряда текущего и предшествующего периодов.
Рассчитать коэффициенты автокорреляции 2-го и последующих уровней можно путем составления аналогичной таблиц. Однако, этот процесс достаточно трудоемок. Для облегчения задачи построим линейные тренды в ППП Exel. Для этого нужно выделить соответствующий диапазон данных (например для расчета 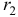 нам нужны данные
нам нужны данные 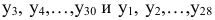 ), затем построить точечную диаграмму и добавить линейный тренд. При построении тренда поставить галочку у флажка «Показывать величину аппроксимации на диаграмме (
), затем построить точечную диаграмму и добавить линейный тренд. При построении тренда поставить галочку у флажка «Показывать величину аппроксимации на диаграмме (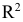 )». Затем из полученного выделить корень квадратный. Для данного примера
)». Затем из полученного выделить корень квадратный. Для данного примера
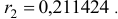
Рассчитаем коэффициенты автокорреляции нескольких уровней. Максимально возможный лаг не должен превышать
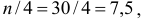
то есть можно рассчитать коэффициенты автокорреляции до 7-го порядка включительно.
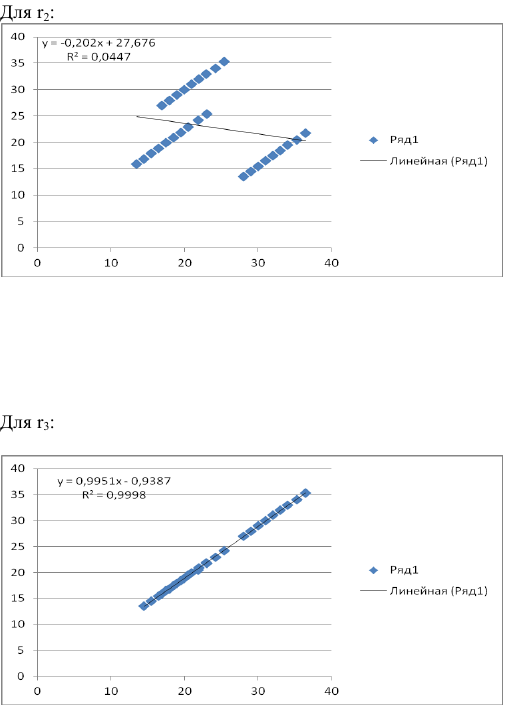
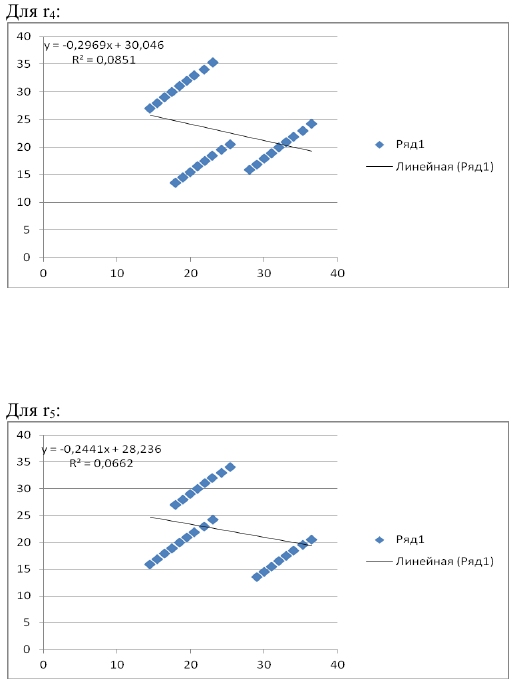
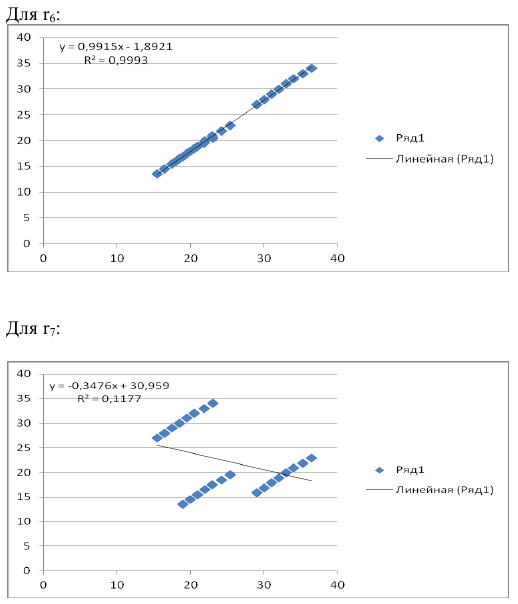
Итак, автокорреляционная функция имеет вид:

Анализ значений автокорреляционной функции позволяет сделать вывод об отсутствии в изучаемом временном ряде сильной линейной тенденции и существовании сезонных колебаний с периодом три 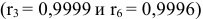 .
.
Для прогнозирования значений 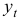 в будущие периоды в данном случае целесообразно предложить уравнение авторегрессии вида:
в будущие периоды в данном случае целесообразно предложить уравнение авторегрессии вида:
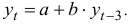
Пример выполненной лабораторной работы № 5. Тема : «Автокорреляции в остатках. Критерий Дарбина-Уотсона»
Задание: По данным за 18 месяцев построено уравнение зависимости прибыли предприятия 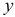 (млн руб.) от цен на сырье
(млн руб.) от цен на сырье 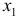 (тыс. руб. за 1 т) и производительности труда
(тыс. руб. за 1 т) и производительности труда 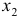 (ед. продукции на 1 работника):
(ед. продукции на 1 работника):
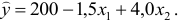
При анализе остаточных величин были использованы значения, приведенные в таблице 7.2.1.

Требуется:
- По трем позициям рассчитать
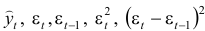 .
. - Рассчитать критерий Дарбина — Уотсона.
- Оценить полученный результат при 5%-м уровне значимости.
- Указать, пригодно ли данное уравнение для прогноза.
Решение:
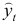 определяется путем подстановки фактических значений и в уравнение регрессии:
определяется путем подстановки фактических значений и в уравнение регрессии:
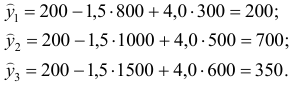
Остатки рассчитываются по формуле 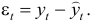 Следовательно,
Следовательно,
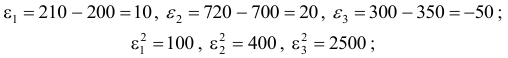
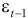 — те же значения, что и
— те же значения, что и 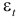 , но со сдвигом на один месяц.
, но со сдвигом на один месяц.
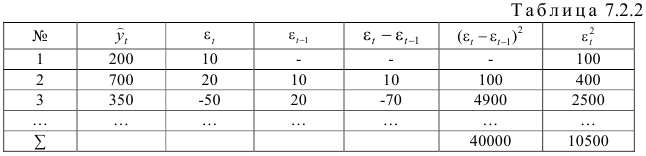
Результаты вычислений оформим в виде таблицы 7.2.2
- Критерий Дарбина — Уотеона рассчитывается по формуле:
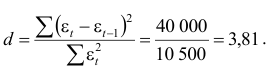
- Выдвигаем гипотезу
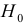 об отсутствии автокорреляции в остатках. Определяем табличное значение статистики Дарбина — Уотеона. При уровне значимости
об отсутствии автокорреляции в остатках. Определяем табличное значение статистики Дарбина — Уотеона. При уровне значимости 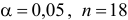 (месяцев) и
(месяцев) и 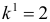 (число факторов) нижнее значение равно
(число факторов) нижнее значение равно 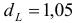 , а верхнее
, а верхнее 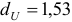 . Чтобы оценить значимость коэффициента автокорреляции вычислим интервалы:
. Чтобы оценить значимость коэффициента автокорреляции вычислим интервалы:
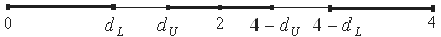
В данной задаче
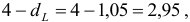
то есть
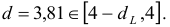
Это означает наличие отрицательной автокорреляции в остатках.
- Уравнение не может быть использовано для прогноза, так как в нем не устранена автокорреляция в остатках, которая может иметь различные причины: возможно, в уравнение не включен какой-либо существенный фактор, либо неточна форма связи, а, может быть, в рядах динамики имеется общая тенденция.
Возможно эти страницы вам будут полезны:
- Предмет эконометрика
- Примеры решения задач по эконометрике
- Курсовая работа по эконометрике
- Заказать работу по эконометрике
- Помощь по эконометрике
- Решение задач по эконометрике в Excel
- Системы эконометрических уравнений